When using Redis Writer to write data to Redis, if the Value type is List, the synchronization result of rerunning the sync task will not be idempotent. Therefore, if the Value type is List, you need to manually clear the corresponding data in Redis before rerunning the sync task.
Offline Single Table Write Node Configuration for TencentDB for Redis
Parameters
Description
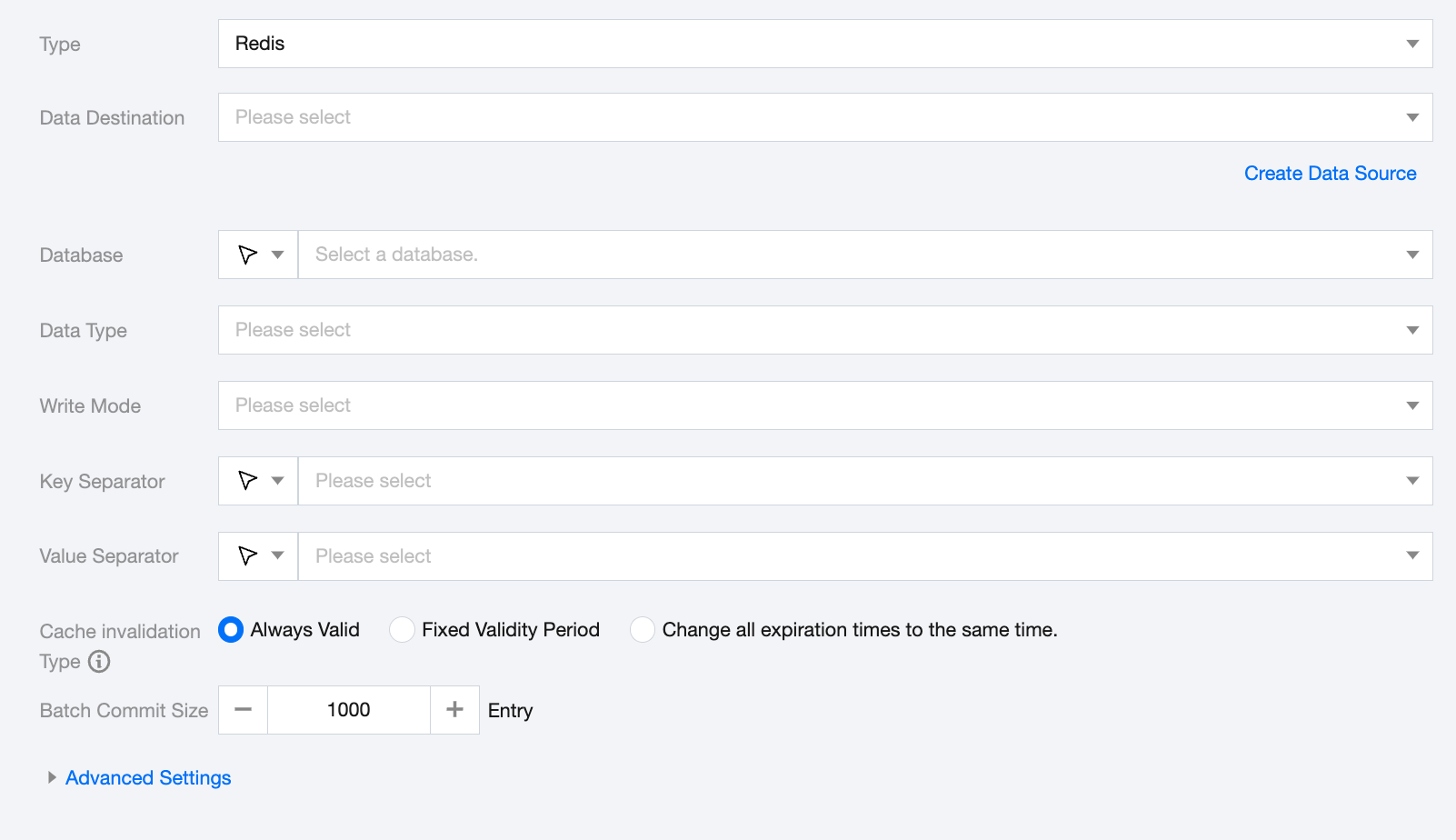
Data Destination
Select the available TencentDB for Redis data source in the current project.
Database
Supports selection or manual input of the database name to write to
The Redis-generated databases 0-15 are used as the default databases.
If the data source network is not connected and the database information cannot be fetched directly, you can manually enter the database name. Data synchronization can still be performed when the Data Integration network is connected.
Data Type
The value types written in TencentDB for Redis include the following 5 types:
String
List
Set
Zset
Hash
The data type configuration may slightly differ for different value types.
Write Mode
Automatically fill in the corresponding write mode based on the write type.
Key Separator
The key separator for writing to TencentDB for Redis must match the field separator of the created TencentDB for Redis table; otherwise, data cannot be found in the table. Options: '\t', '\u001', '|', ' ', ';', ','.
Value Separator
The value separator for writing to TencentDB for Redis must match the value separator of the created TencentDB for Redis table; otherwise, data cannot be found in the table. Options: '\t', '\u001', '|', ' ', ';', ','.
Cache invalidation Type
Three expiration types are supported:
Always Valid: The key value is set without an expiration time and remains valid indefinitely.
Fixed Validity Period: Data expires after a fixed period from the time of actual batch writing.
Change all expiration times to the same time: All written data expires together at a specified time.
Batch Commit Size
The size of the records submitted in one batch. This value can greatly reduce the number of network interactions between the data synchronization system and Redis, improving overall throughput. However, setting this value too high can result in Out of Memory (OOM) exceptions during the data synchronization process.
Advanced Settings (Optional)
You can configure parameters according to business needs.
Data Type
Value Type
type parameter (Required)
mode parameter (Required)
valueFieldDelimiter parameter (Optional)
writeMode Configuration Example
String
type should be configured as string.
mode is the write mode parameter. When the value is a string: mode should be configured as set. If the data to be stored already exists, it will overwrite the existing data.
valueFieldDelimiter
As a separator between values, the default value is \u0001. This configuration is mainly used when there are more than two columns per row in the source data. For example, when there are three columns, each column is separated by the delimiter, such as value1\u0001value2\u0001value3. If the source data has only two columns (i.e., key and value), then no configuration is needed.
mode is the write mode parameter. When the value is a string set, mode should be configured as sadd, indicating storing data in the set. If the data to be stored already exists, it will overwrite the existing data.
mode is the write mode parameter. When the value is an ordered string collection, mode should be configured as zadd, indicating storing data in the ordered collection. If the data to be stored already exists, it will overwrite the existing data.
No need to configure this parameter.
"writeMode":{
"type": "zset","mode": "zadd"
}
When the value type is zset, each row of the source data must follow the corresponding specifications. That is, apart from the key, each row can only have one pair of score and value, and the score must precede the value for Redis Writer to parse whether the column corresponds to score or value.
Hash
type should be configured as hash.
mode is the write mode parameter. When the value is a hash, mode should be configured as hset, indicating storing data in the hash ordered collection. If the data to be stored already exists, it will overwrite the existing data.
No need to configure this parameter.
"writeMode":{
"type": "hash","mode": "hset"
}
When the value type is hash, each row of the source data must follow the corresponding specifications. That is, apart from the key, each row can only have one pair of attribute and value, and the attribute must precede the value for Redis Writer to parse whether the column corresponds to attribute or value.