Tencent Cloud WeData
- Product Introduction
- Purchase Guide
- Execute Resource Purchase Description
- Preparations
- Operation Guide
- Console Operation
- Execution Resource Group Configuration
- Approval Management
- General Configuration
- Project Management
- Project Execution Resource Group
- Data Integration
- Integration resource configuration and management
- Real-time Synchronization Task Configuration and Operation and Maintenance
- Data Sources Supported by Real-time Synchronization
- Data Source List
- Whole Database Synchronization Task Configuration
- Single Table Synchronization Task Configuration
- Real-time synchronization operation and maintenance
- Real-time OPS
- Monitoring and Alarms
- Offline Synchronization Task Configuration and Operation and Maintenance
- Data Sources Supported by Offline Synchronization
- Data Source List
- DataInLong Offline Synchronization Configuration and Operation and Maintenance
- Data Development:Offline Synchronization, Configuration and Ops
- Offline Synchronization and Ops
- Practical Tutorial
- Data Development
- Engine User Guide
- Task Development
- Task Node Type
- General Node
- Task Scheduling Configuration
- Development Space
- Task Operation and Maintenance
- Data Analysis
- Data Assets
- Data Map
- Metadata Collection
- Metadata Management
- My Data
- My Responsibilities
- Managed by Me
- Configuration Management
- Data Security
- Data protection
- API Documentation
- Making API Requests
- Smart Ops Related Interfaces
- Data Development APIs
- Data Operations Related Interfaces
- Metadata Related Interfaces
- Task Operations APIs
- Instance Operation and Maintenance Related Interfaces
- Data Map and Data Dictionary APIs
- Data Quality Related Interfaces
- DataInLong APIs
- Platform management related APIs
- Data Source Management APIs
- Asset Data APIs
- Related Agreement

DocumentationTencent Cloud WeDataOperation GuideData DevelopmentTask DevelopmentTask Node TypeDLCDLC SQL
DLC SQL

Last updated: 2025-03-12 22:24:44
Note:
Bind the DLC engine. Currently, Spark SQL, Spark jobs, and Presto engines are supported. For details about the engine kernel, see DLC Engine Kernel Version.
1. The current user needs permissions for the corresponding DLC computational resource and database and table.
2. The corresponding database and table have been created in DLC.
Feature Description
Submit a DLC SQL task execution to WeData's workflow scheduling platform. When selecting the DLC data source type, provide more advanced settings to support the configuration of Presto and Sparksql parameters.
When using the Spark job engine, you can configure job resource specifications and parameters. Resource configuration must not exceed the limits of the computational resources themselves.
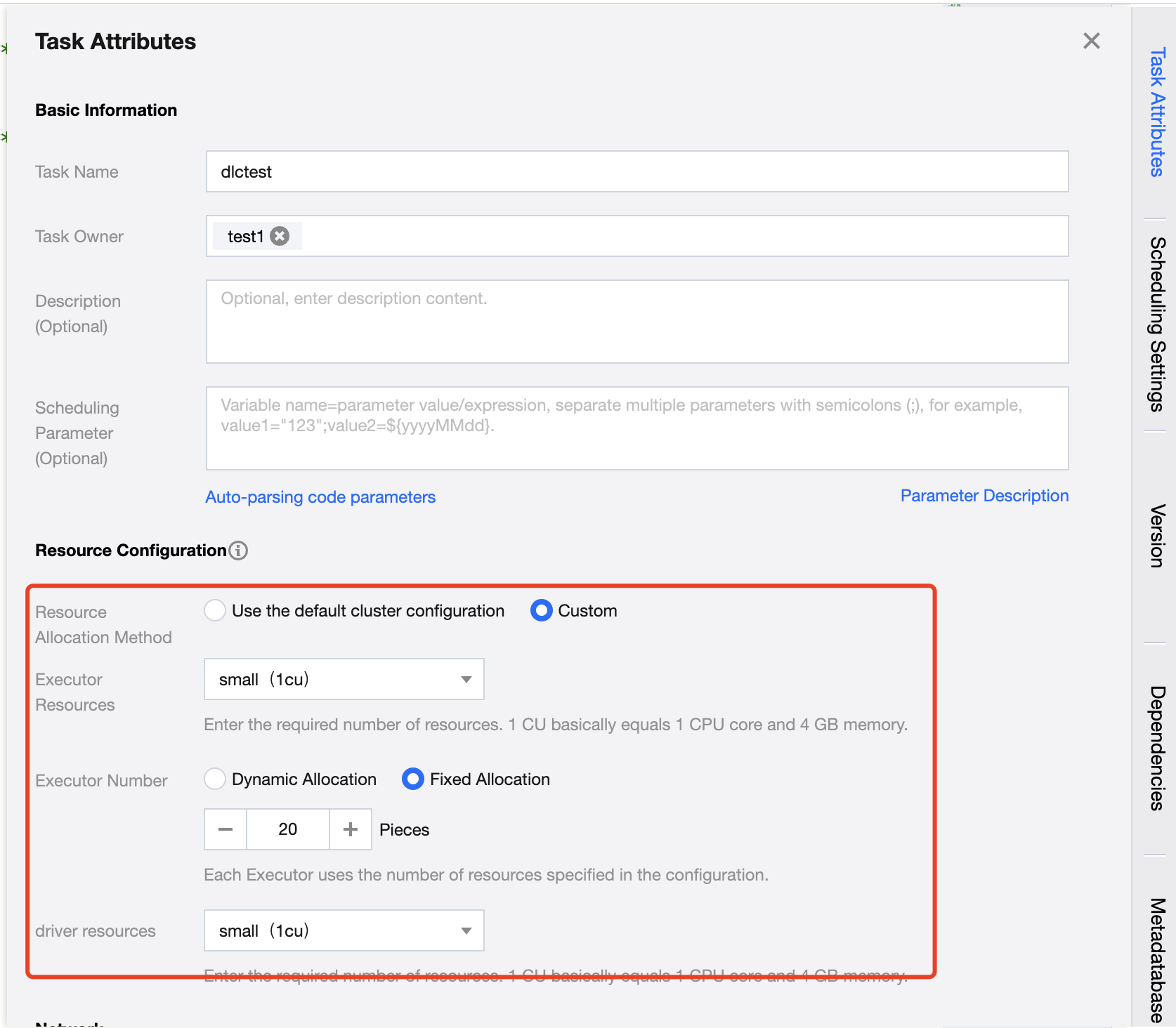
Configuration Description:
Configuration Item | Description |
Resource Configuration Method | Divided into two methods: cluster default configuration and custom configuration 1. Use cluster default configuration Use the current task computational resource cluster configuration 2. Customize User customizes Executor and Driver configurations. |
Executor resource | Enter the required resource count. 1 cu is roughly equivalent to 1 core CPU and 4 GB memory. 1. Small: A single calculation unit (1 cu) 2. Medium: Two calculation units (2 cu) 3. Large: Four calculation units (4 cu) 4. Xlarge: Eight calculation units (8 cu) |
Number of Executors | An Executor is a compute node or compute instance responsible for executing tasks and handling computing work. The resources used by each Executor are the configured number of resources. |
driver resource | Enter the required number of Driver resources. 1 cu is roughly equivalent to 1 core CPU and 4 GB memory. 1. Small: A single calculation unit (1 cu) 2. Medium: Two calculation units (2 cu) 3. Large: Four calculation units (4 cu). 4. Xlarge: Eight calculation units (8 cu). |
Sample Code
-- Create a user information tablecreate table if not exists wedata_demo_db.user_info (user_id string COMMENT 'User ID'user_name string COMMENT 'username'user_age int COMMENT 'age'city string COMMENT 'City') COMMENT 'User information table';-- Insert data into the user information tableinsert into wedata_demo_db.user_info values ('001', 'Zhang San', 28, 'beijing');insert into wedata_demo_db.user_info values ('002', 'Li Si', 35, 'shanghai');insert into wedata_demo_db.user_info values ('003', 'Wang Wu', 22, 'shenzhen');insert into wedata_demo_db.user_info values ('004', 'Zhao Liu', 45, 'guangzhou');insert into wedata_demo_db.user_info values ('005', 'Xiao Ming', 20, 'beijing');insert into wedata_demo_db.user_info values ('006', 'Xiao Hong', 30, 'shanghai');insert into wedata_demo_db.user_info values ('007', 'Xiao Gang', 25, 'shenzhen');insert into wedata_demo_db.user_info values ('008', 'Xiao Li', 40, 'guangzhou');insert into wedata_demo_db.user_info values ('009', 'Xiao Zhang', 23, 'beijing');insert into wedata_demo_db.user_info values ('010', 'Xiao Wang', 50, 'shanghai');select * from wedata_demo_db.user_info;
Note:
When using Iceberg external tables, the SQL syntax differs from that of Iceberg native tables. For details, see DLC Iceberg External Table and Native Table Syntax Differences.
Presto Engine Example Code
Applicable table types: native Iceberg tables, external Iceberg tables.
CREATE TABLE `cpt_demo`.`dempts` (id bigint COMMENT 'id number',num int,eno float,dno double,cno decimal(9,3),flag boolean,data string,ts_year timestamp,date_month date,bno binary,point struct<x: double, y: double>,points array<struct<x: double, y: double>>,pointmaps map<struct<x: int>, struct<a: int>>)COMMENT 'table documentation'PARTITIONED BY (bucket(16, id), years(ts_year), months(date_month), identity(bno), bucket(3, num), truncate(10, data));
SparkSQL Engine Example Code
Applicable table types: native Iceberg tables, external Iceberg tables.
CREATE TABLE `cpt_demo`.`dempts` (id bigint COMMENT 'id number',num int,eno float,dno double,cno decimal(9,3),flag boolean,data string,ts_year timestamp,date_month date,bno binary,point struct<x: double, y: double>,points array<struct<x: double, y: double>>,pointmaps map<struct<x: int>, struct<a: int>>)COMMENT 'table documentation'PARTITIONED BY (bucket(16, id), years(ts_year), months(date_month), identity(bno), bucket(3, num), truncate(10, data));
SparkSQL Job Engine Example Code
Applicable table types: native Iceberg tables, external Iceberg tables.
CREATE TABLE `cpt_demo`.`dempts` (id bigint COMMENT 'id number',num int,eno float,dno double,cno decimal(9,3),flag boolean,data string,ts_year timestamp,date_month date,bno binary,point struct<x: double, y: double>,points array<struct<x: double, y: double>>,pointmaps map<struct<x: int>, struct<a: int>>)COMMENT 'table documentation'PARTITIONED BY (id, ts_year, date_month);
Notes:
Was this page helpful?
You can also Contact Sales or Submit a Ticket for help.
Yes
No