Data Integration provides MySQL reading and writing capabilities. This article introduces the pre-environment configuration for real-time data synchronization using MySQL and the current capability support.
Supported Versions
Currently, Data Integration supports real-time reading at the single table and whole database levels for MySQL. To use the real-time reading capability, the following version limitations must be observed:
Data Source Type
Edition
Driver
MySQL
5.6,5.7,8.0.x
JDBC Driver:8.0.21
RDS MySQL
5.6,5.7, 8.0.x
PolarDB MySQL
5.6,5.7,8.0.x
Aurora MySQL
5.6,5.7,8.0.x
MariaDB
10.x
PolarDB X
2.0.1
Use Limits
You need to enable Binlog logging and support the synchronization of MySQL server Binlog configuration format as ROW.
Tables without primary keys may have data duplication since exactly once cannot be guaranteed. Therefore, it is best to ensure the table has a primary key for real-time sync tasks.
XA ROLLBACK is not supported. Real-time synchronization tasks will not perform rollback operations on data prepared by XA PREPARE. If you need to handle XA ROLLBACK scenarios, you need to manually remove the XA ROLLBACK tables from the real-time synchronization task, re-add the tables, and then synchronize again.
Set MySQL Session Timeout:
When creating an initial consistent snapshot for a large database, the connection you establish may timeout while reading the tables. You can prevent this behavior by configuring interactive_timeout and wait_timeout in the MySQL configuration file.
Data Integration has version requirements for MySQL. Check if the MySQL version to be synchronized meets the version requirements. You can check the current MySQL database version using the following statement in the MySQL database.
select version();
Set MySQL Server Permissions
You must define a MySQL user with appropriate permissions on all databases monitored by the Debezium MySQL Connector.
In real-time data synchronization, the account must have SELECT, REPLICATION SLAVE, and REPLICATION CLIENT permissions on the database. Refer to the following command to execute:
RELOAD permission is no longer required when scan.incremental.snapshot.enabled is enabled (enabled by default).
3. Refresh the user's permissions:
mysql>FLUSH PRIVILEGES;
Enabling MySQL Binlog
1. Check whether the binlog is enabled
show variables like"log_bin";
When the result returns as ON, it indicates that Binlog is enabled. If it is a standby database, use the following statement:
show variables like"log_slave_updates";
If the return is ON, it indicates that Binlog is enabled. If Binlog is already enabled, you can skip the following steps.
2. Enabling Binlog
If it is confirmed that the Binlog is not enabled, the following operations are required:
For Tencent Cloud instance MySQL, Binlog is enabled by default.
For open-source MySQL, refer to the official documentation to enable binlog.
3. Change Binlog Format to Row
Real-time synchronization only supports the MySQL server Binlog configuration format as ROW. Use the following statement to check the Binlog usage format.
show variables like"binlog_format";
If the return is not ROW, please modify the Binlog Format.
For open-source MySQL, refer to the official documentation:
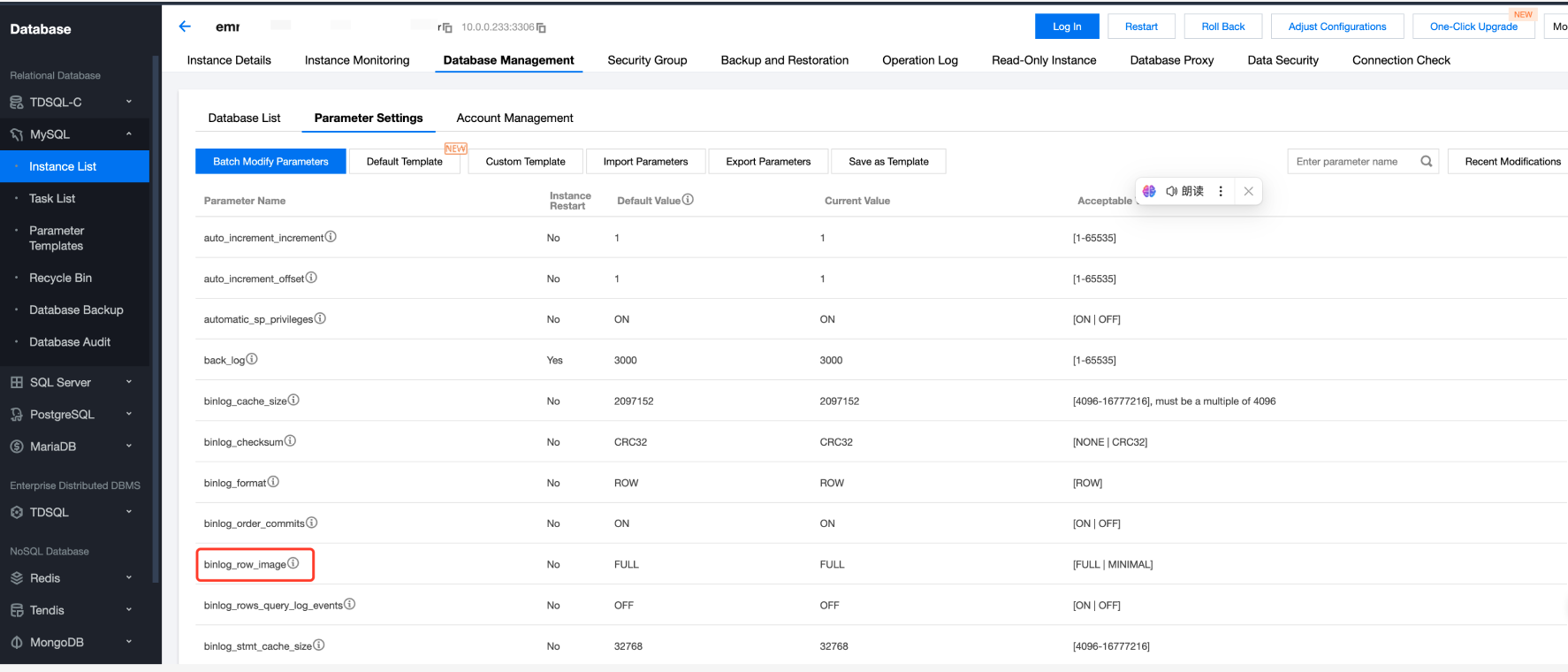
Log in to the Tencent Cloud MySQL console, find the instance for which you want to enable Binlog, and click to enter the detailed information page of the instance.
In the top tabs, select DMC and find the Parameter Settings tab.
In the Parameter Settings tab, find the binlog_format parameter and set it to "ROW".
4. binlog_row_image
Real-time synchronization only supports the MySQL server binlog_row_image configuration format as FULL or full.
Use the following statement to query the format of binlog_row_image.
show variables like"binlog_row_image";
If the return is not FULL/full, please modify binlog_row_image:
For open-source MySQL, refer to the official documentation:
Log in to the Tencent Cloud MySQL console, find the instance for which you want to enable Binlog, and click to enter the detailed information page of the instance.
In the top tabs, select DMC and find the Parameter Settings tab.
In the Parameter Settings tab, find the binlog_row_image parameter and set it to "FULL".
Enable GTIDs (optional)
GTID (Global Transaction Identifier) uniquely identifies a transaction in the binlog. Using GTID can avoid data chaos or master-slave inconsistency caused by transaction re-execution.
Enable Process
1. Check if GTID is enabled
showglobal variables like'%GTID%';
The return result is similar to the following, indicating GTID is enabled.
For Tencent Cloud instance MySQL, it is enabled by default and cannot be disabled.
Real-time full-database source configuration
Data source settings
Parameter
Description
Data Source
Select the MySQL data source to be synchronized.
Source Table
All databases and tables: Monitor all databases under the data source. Newly added databases and tables during the task run will be synchronized to the target by default.
Specific table: Under this option, you need to specify the exact table name. After setting, the task will only synchronize the specified table; if you need to add a new table for synchronization, you need to stop and restart the task.
Specific database: Under this option, you need to specify the exact database name, using regular expression for table names. After setting, new tables that match the table name expression during the task run will be synchronized to the target by default.
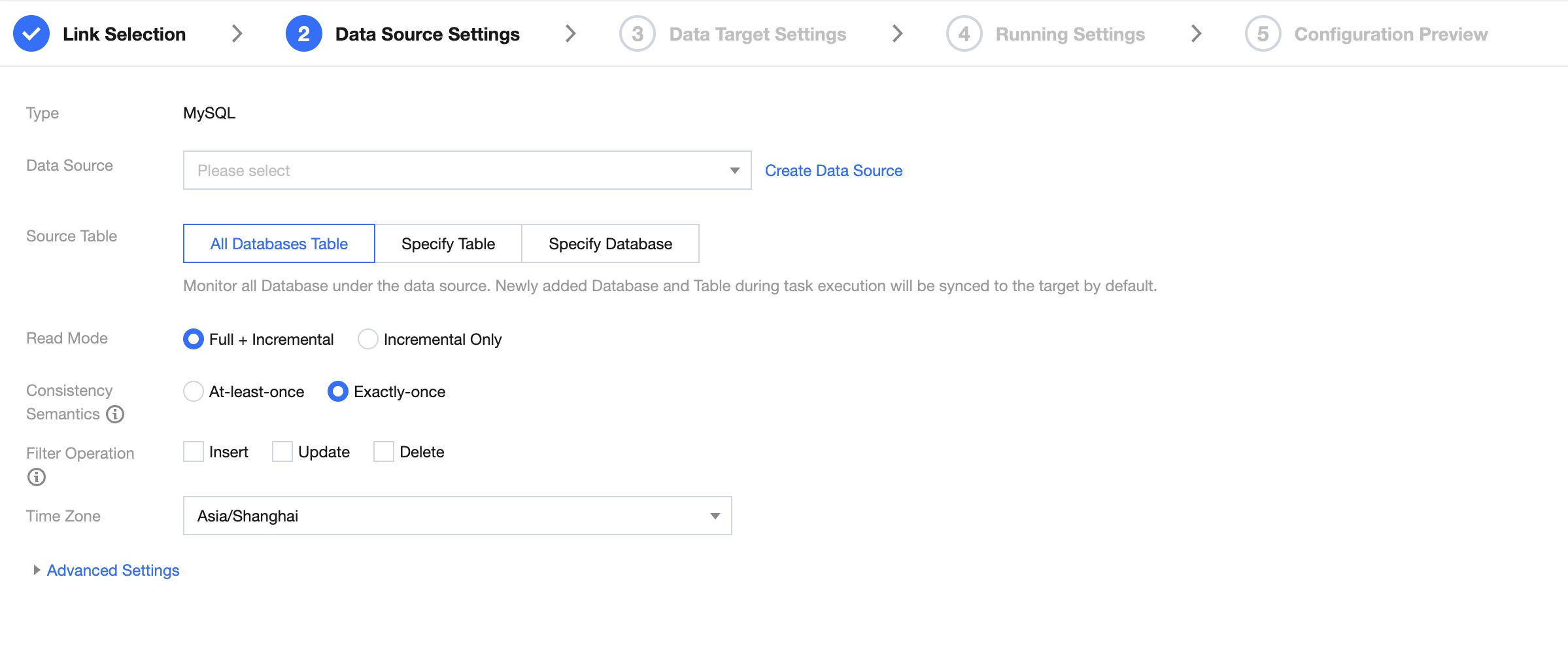
Read Mode
Full + Increment: Data synchronization is divided into full and increment phases. After the full phase is completed, the task enters the increment phase. The full phase will synchronize historical data in the database, and the incremental phase starts synchronizing from the binlog cdc location after the task starts.
Increment Only: Only synchronize data from the binlog cdc position after the task starts.
Consistency Semantics
Only represents the consistency semantics of the reading end. Supports At-least-once and Exactly-once.
At-least-once: Data may be read more than once, relying on the destination end's deduplication to ensure data consistency. Suitable for scenarios with large data volumes in the full phase and using non-numeric primary keys, with high synchronization performance requirements.
Exactly-once: Data is read strictly once, with some performance losses. Tables without a primary key and unique index column are not supported. Suitable for general scenarios where the source table has a numeric primary key or unique index column.
The current version's two modes are state-incompatible. If the mode is changed after task submission, stateful restart is not supported.
Filter Operation
Supports three operations: insert, update, and delete. Data of the specified operation type will not be synchronized when set.
Time Zone
Set the timezone for log time, default is Shanghai.
Sync gh-ost temporary table
The business scenario for gh-ost is to perform online table structure changes in MySQL, known as Online DDL, without affecting normal business operations. It can solve problems such as table locks, performance degradation, and synchronization delays caused by traditional alter table or create index commands. It is suitable for scenarios where table modifications are needed, such as adding new columns, adding indexes, modifying field types, etc.
Pre-requisites for using gh-ost:
gh-ost must have access to MySQL.
If MySQL is Tencent Cloud's CDB, you need to add the --aliyun-rds parameter to the gh-ost execution command.
During the execution of the gh-ost tool, the rule for generating temporary tables is ^_(.*)_(gho|ghc|del)$, where (.*) is the name of the table being changed. Custom names for temporary tables are not supported.
For other gh-ost limitations, you can refer to gh-ost/requirements-and-limitations.md at master · github/gh-ost · GitHub.
To sync gh-ost temporary tables, you need to turn on this switch. Once enabled, it will monitor '_tablename_gho', '_tablename_ghc', '_tablename_del', and sync changes to the '_tablename_gho' table.
Advanced Settings (optional)
You can configure parameters according to business needs.
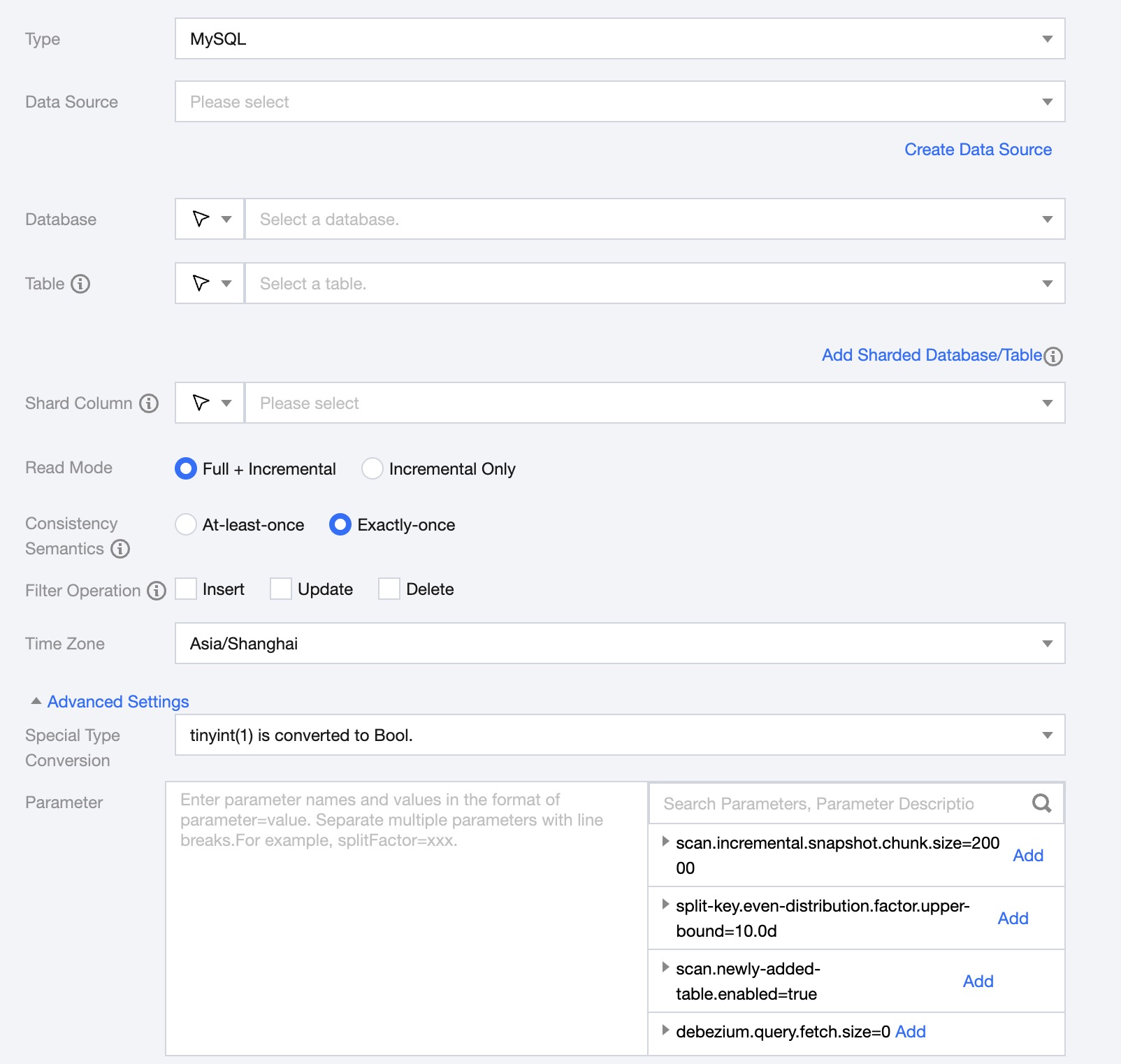
During MySQL full-database synchronization, tasks use the primary key or unique index (if no primary key) to split. Currently supported primary key types include:
Support selecting or manually entering the name of the required database.
By default, the database bound to the data source is used as the default database. Other databases need to be manually entered.
If the data source network is not connected and the database information cannot be fetched directly, you can manually enter the database name. Data synchronization can still be performed when the Data Integration network is connected.
Table
Support selecting or manually entering the table name to be read.
In the case of table partitioning, you can select or enter multiple table names on the MySQL source end. Multiple tables need to have consistent structures.
In the case of partitioned tables, you can configure the table index range. For example, 'table_[0-99]' indicates reading 'table_0','table_1','table_2' up to 'table_99'. If your table number suffix length is consistent, such as 'table_000','table_001','table_002' up to 'table_999', you can configure it as '"table": ["table_00[0-9]", "table_0[10-99]", "table_[100-999]"]'.
If the data source network is not connected and the table information cannot be fetched directly, you can manually enter the table name. Data synchronization can still be performed when the Data Integration network is connected.
Add Shared Database/Table
Applicable to sharding scenarios. Click to configure multiple data sources, databases, and table information. In sharding scenarios, ensure all table structures are consistent. The task configuration will default to displaying and using the structure of the first table to obtain data.
Shard Column
The shard column is used to divide the table into multiple shards for synchronization. It is recommended to prioritize using the primary key of the table as the shard column for tables with primary keys; for tables without primary keys, it is recommended to choose indexed columns as the shard column, and ensure that the shard column does not have data update operations, otherwise only At-Least-Once semantics can be guaranteed.
Read Mode
Full + Increment: Data synchronization is divided into full and increment phases. After the full phase is completed, the task enters the increment phase. The full phase will synchronize historical data in the database, and the incremental phase starts synchronizing from the binlog cdc location after the task starts.
Increment Only: Only synchronize data from the binlog cdc position after the task starts.
Consistency Semantics
Only represents the consistency semantics of the reading end. Supports At-least-once and Exactly-once.
At-least-once: Data may be read more than once, relying on the destination end's deduplication to ensure data consistency. Suitable for scenarios with large data volumes in the full phase and using non-numeric primary keys, with high synchronization performance requirements.
Exactly-once: Data is read strictly once, with some performance losses. Tables without a primary key and unique index column are not supported. Suitable for general scenarios where the source table has a numeric primary key or unique index column.
The current version's two modes are state-incompatible. If the mode is changed after task submission, stateful restart is not supported.
Filter Operation
Once set, data for the specified operation type will not be synchronized; supports filtering insert, update, and delete operations.
Time Zone
Set the timezone for log time, default is Shanghai.
Special Type Conversion
Map tinyint(1) to bool or tinyint, default to bool.
Parameter (optional)
You can configure parameters according to business needs.
Real-time Single Table Write Node Configuration
Parameter
Description
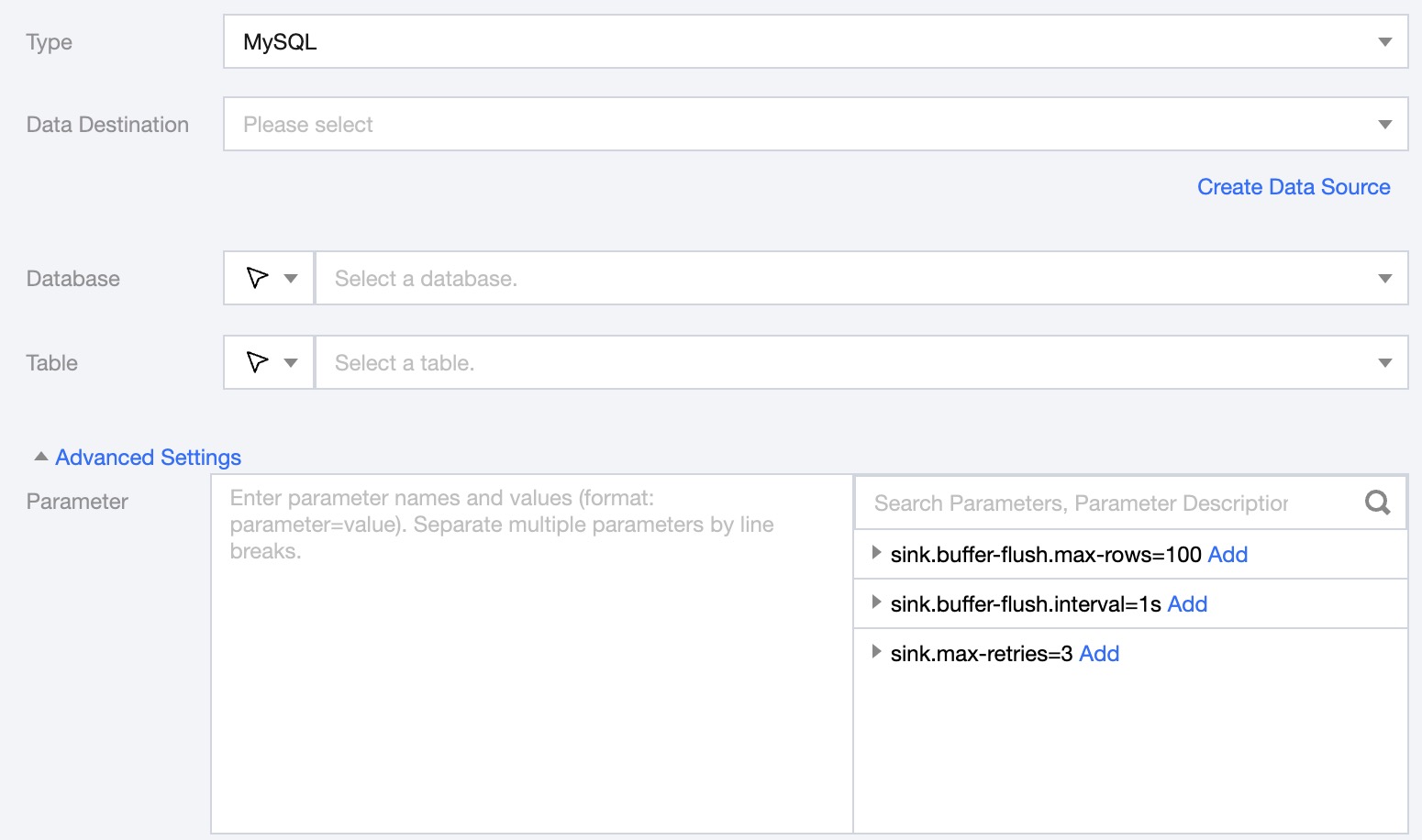
Data Destination
Select MySQL data source.
Database
Support selecting or manually entering the name of the required database.
By default, the database bound to the data source is used as the default database. Other databases need to be manually entered.
If the data source network is not connected and the database information cannot be fetched directly, you can manually enter the database name. Data synchronization can still be performed when the Data Integration network is connected.
Table
Support selecting or manually entering the table name to be read.
If the data source network is not connected and the table information cannot be fetched directly, you can manually enter the table name. Data synchronization can still be performed when the Data Integration network is connected.
Parameter (optional)
You can configure parameters according to business needs.
Log collection write node
1. Enter Data Integration Real-Time Synchronization > Log Collection page, select MySQL type as the target end.
Parameter
Description
Data Destination
Select the available MySQL data source in the current project.
Database
Select the corresponding database in the data source.
Table
Select the corresponding table in the data source.
Advanced Settings (optional)
You can configure parameters according to business needs.
Read/Write data type conversion support
Read
The data types supported by MySQL read and their conversion relationships are as follows (when processing MySQL, the data type of the MySQL data source will be mapped to the data type of the data processing engine first)
Field Type
Supported
Internal Mapping Fields
Remarks
TINYINT
Yes
TINYINT
TINYINT(1) maps to BOOLEAN
Add an option to support mapping TINYINT(1) to either bool or tinyint
SMALLINT
Yes
SMALLINT
-
TINYINT_UNSIGNED
Yes
SMALLINT
-
TINYINT_UNSIGNED_ZEROFILL
Yes
SMALLINT
-
INT
Yes
INT
-
INTEGER
Yes
INT
-
YEAR
Yes
INT
-
MEDIUMINT
Yes
INT
-
SMALLINT_UNSIGNED
Yes
INT
-
SMALLINT_UNSIGNED_ZEROFILL
Yes
INT
-
BIGINT
Yes
LONG
-
INT_UNSIGNED
Yes
LONG
-
MEDIUMINT_UNSIGNED
Yes
LONG
-
MEDIUMINT_UNSIGNED_ZEROFILL
Yes
LONG
-
INT_UNSIGNED_ZEROFILL
Yes
LONG
-
BIGINT_UNSIGNED
Yes
DECIMAL
DECIMAL(20,0)
BIGINT_UNSIGNED_ZEROFILL
Yes
DECIMAL
DECIMAL(20,0)
SERIAL
Yes
DECIMAL
DECIMAL(20,0)
FLOAT
Yes
FLOAT
-
FLOAT_UNSIGNED
Yes
FLOAT
-
FLOAT_UNSIGNED_ZEROFILL
Yes
FLOAT
-
DOUBLE
Yes
DOUBLE
-
DOUBLE_UNSIGNED
Yes
DOUBLE
-
DOUBLE_UNSIGNED_ZEROFILL
Yes
DOUBLE
-
DOUBLE_PRECISION
Yes
DOUBLE
-
DOUBLE_PRECISION_UNSIGNED
Yes
DOUBLE
-
ZEROFILL
Yes
DOUBLE
-
REAL
Yes
DOUBLE
-
REAL_UNSIGNED
Yes
DOUBLE
-
REAL_UNSIGNED_ZEROFILL
Yes
DOUBLE
-
NUMERIC
Yes
DECIMAL
Using the actual precision of the user database p<=38 maps to DECIMAL, 38 < p <= 65 maps to String
NUMERIC_UNSIGNED
Yes
DECIMAL
Using the actual precision of the user database p<=38 maps to DECIMAL, 38 < p <= 65 maps to String
NUMERIC_UNSIGNED_ZEROFILL
Yes
DECIMAL
Using the actual precision of the user database p<=38 maps to DECIMAL, 38 < p <= 65 maps to String
DECIMAL
Yes
DECIMAL
Using the actual precision of the user database p<=38 maps to DECIMAL, 38 < p <= 65 maps to String
DECIMAL_UNSIGNED
Yes
DECIMAL
Using the actual precision of the user database p<=38 maps to DECIMAL, 38 < p <= 65 maps to String
DECIMAL_UNSIGNED_ZEROFILL
Yes
DECIMAL
Using the actual precision of the user database p<=38 maps to DECIMAL, 38 < p <= 65 maps to String
FIXED
Yes
DECIMAL
Using the actual precision of the user database p<=38 maps to DECIMAL, 38 < p <= 65 maps to String
FIXED_UNSIGNED
Yes
DECIMAL
Using the actual precision of the user database p<=38 maps to DECIMAL, 38 < p <= 65 maps to String
FIXED_UNSIGNED_ZEROFILL
Yes
DECIMAL
Using the actual precision of the user database p<=38 maps to DECIMAL, 38 < p <= 65 maps to String
BOOLEAN
Yes
BOOLEAN
-
DATE
Yes
DATE
-
TIME
Yes
TIME
-
DATETIME
Yes
TIMESTAMP
-
TIMESTAMP
Yes
TIMESTAMP
-
CHAR
Yes
STRING
-
JSON
Yes
STRING
-
BIT
Yes
STRING
BIT(1) mapped to BOOLEAN
VARCHAR
Yes
STRING
-
TEXT
Yes
STRING
-
BLOB
Yes
STRING
-
TINYBLOB
Yes
STRING
-
TINYTEXT
Yes
STRING
-
MEDIUMBLOB
Yes
STRING
-
MEDIUMTEXT
Yes
STRING
-
LONGBLOB
Yes
STRING
-
LONGTEXT
Yes
STRING
-
VARBINARY
Yes
STRING
-
GEOMETRY
Yes
STRING
-
POINT
Yes
STRING
-
LINESTRING
Yes
STRING
-
POLYGON
Yes
STRING
-
MULTIPOINT
Yes
STRING
-
MULTILINESTRING
Yes
STRING
-
MULTIPOLYGON
Yes
STRING
-
GEOMETRYCOLLECTION
Yes
STRING
-
ENUM
Yes
STRING
-
BINARY
Yes
BINARY
BINARY(1)
SET
No
-
Write
The data types supported by MySQL write and their conversion relationships are as follows:
Internal Type
MySQL Type
TINYINT
TINYINT
SMALLINT
SMALLINT,TINYINT UNSIGNED
INT
INT,MEDIUMINT,SMALLINT UNSIGNED
BIGINT
BIGINT,INT UNSIGNED
DECIMAL(20, 0)
BIGINT UNSIGNED
FLOAT
FLOAT
DOUBLE
DOUBLE,DOUBLE PRECISION
DECIMAL(p, s)
NUMERIC(p, s),DECIMAL(p, s)
BOOLEAN
BOOLEAN,TINYINT(1)
DATE
DATE
TIME [(p)][WITHOUT TIMEZONE]
TIME [(p)]
TIMESTAMP [(p)][WITHOUT TIMEZONE]
DATETIME [(p)]
STRING
CHAR(n),VARCHAR(n),TEXT
BYTES
BINARY,VARBINARY,BLOB
ARRAY
-
FAQs
MySQL serverid conflict
Error message:
com.github.shyiko.mysql.binlog.network.ServerException:A slave withthe same server_uuid/server_id as this slave has connected tothe master.
Solution: We have optimized the generation of server IDs to be random. For previous tasks, if a server ID is explicitly set in the MySQL advanced parameters, it is recommended to delete it to avoid conflicts caused by multiple tasks using the same data source with the same server ID.
Report binlog file not found error information:
Error message:
Caused by:org.apache.kafka.connect.errors.ConnectException:The connector is trying toread binlog starting at GTIDs xxx and binlog file 'binlog.xxx', pos=xxx, skipping 4 events plus 1 rows, but this is no longer available on the server. Reconfigure the connector touse a snapshot when needed.
Reason:
An error occurs when the Binlog file being read by the job has been cleared on the MySQL server. The reasons for Binlog clearing can vary, such as a short retention period for Binlogs or the job processing speed not keeping up with the Binlog generation speed, exceeding the maximum retention time of MySQL Binlog files. When this happens, the Binlog position being read becomes invalid.
Solution: If the job processing speed cannot keep up with the Binlog generation speed, consider increasing the Binlog retention time or optimizing the job to reduce back pressure and speed up source consumption. If the job status is normal, other database operations might have caused the Binlog to be cleared, making it inaccessible. Review the MySQL database side information to determine the cause of Binlog clearing.
MySQL reported connection reset
Error message:
EventDataDeserializationException:Failedtodeserialize data of EventHeaderV4....Caused by:java.net.SocketException:Connection reset.
Reason:
1. Network issues.
2. The job has back pressure, preventing the source from reading data. The binlog client is idle. If the binlog connection remains idle after a timeout, the MySQL server will disconnect the idle connection.
Solution:
1. If it is a network issue, you can increase MySQL network parameters: set global slave_net_timeout = 120; (default is 30s) set global thread_pool_idle_timeout = 120.
2. If the job back pressure is the cause, you can alleviate it by adjusting the job, such as increasing parallelism, enhancing write speed, and increasing task manager memory to reduce GC.
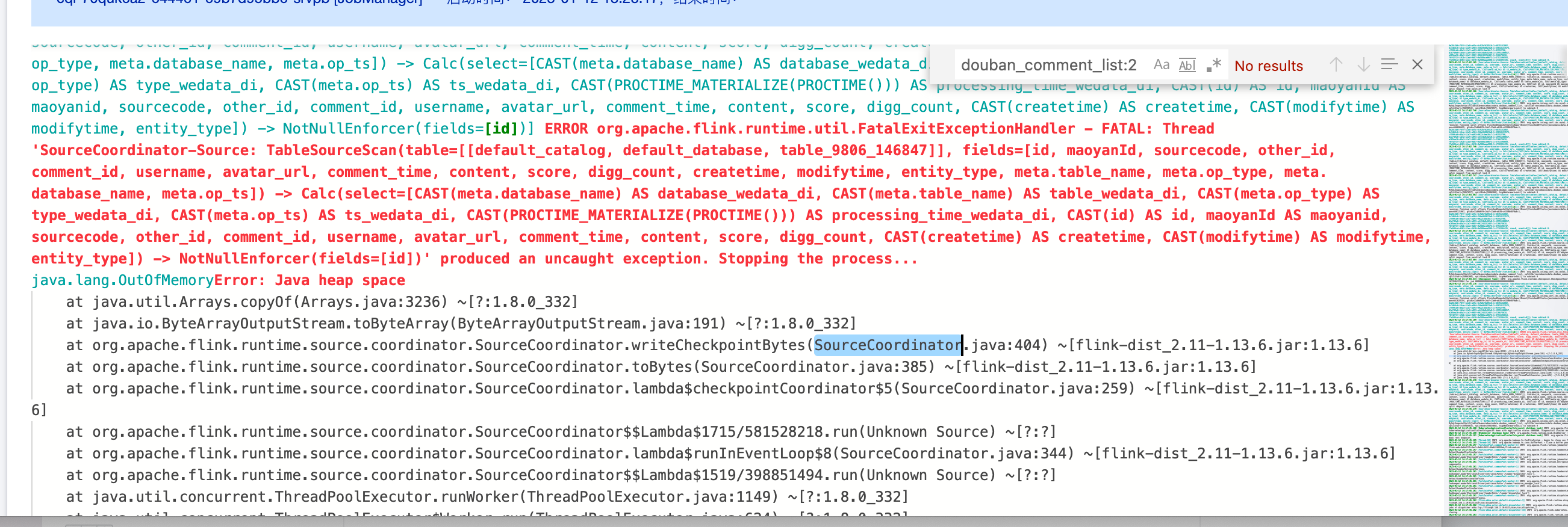
Mysql2dlc task JobManager Oom
Error message:
Reason and solution:
1. If the user has a large amount of data, you can increase the JobManager CU. Use the advanced MySQL parameter scan.incremental.snapshot.chunk.size to increase the chunk size. The default is 8096.
2. If the user data is not large, but the difference between the maximum and minimum primary key values is significant, leading to many chunks when using the equal chunk strategy, modify the distribution factor to apply a non-uniform data split logic: split-key.even-distribution.factor.upper-bound=5.0d. The default distribution factor has already been changed to 10.0d.
User's binlog data format is incorrect, causing debezium parse exception
Error message:
ERROR io.debezium.connector.mysql.MySqlStreamingChangeEventSource[]-Error during binlog processing. Last offset stored =null, binlog reader near position = mysql-bin.000044/211839464.
After setting binlog_row_image=full, restart the database.
Is gh-ost supported?
Yes, it does not migrate temporary table data generated by Online DDL changes, only the original DDL data executed using gh-ost from the source database. You can also use the default or configure your own regular expressions for gh-ost shadow tables and unused tables.