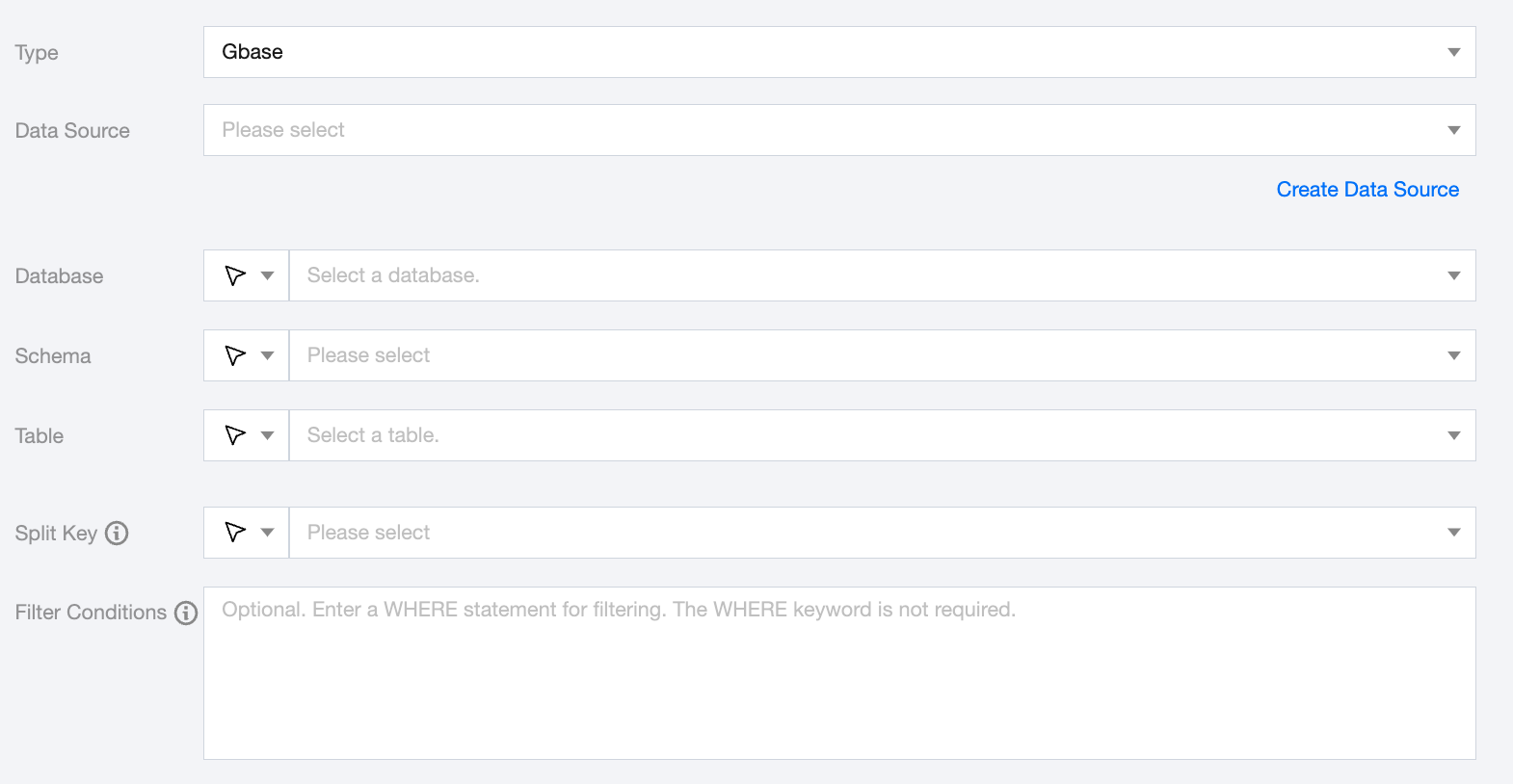
GBase Offline Single Table Read Node Configuration
Parameters
Description
Data Source
Available GBase Data Sources.
Database
Supports selection or manual input of the library name to read from.
By default, the database bound to the data source is used as the default database. Other databases need to be manually entered.
If the data source network is not connected and the database information cannot be fetched directly, you can manually enter the database name. Data synchronization can still be performed when the Data Integration network is connected.
Schema
Supports selection or manual input of the Schema name to be read.
Table
Supports selection or manual input of the table name to be read. Supports simultaneous reading of multiple tables. When configured for multiple tables, you need to ensure that the schema structure of the tables is consistent. GBase does not check the logical consistency of the tables.
Split Key
When extracting data with GBase, if splitPk is specified, it means you wish to sharding data using the field represented by splitPk. As a result, concurrent tasks for Data Synchronization will be initiated to improve the efficiency of Data Synchronization.
It is recommended to use the table primary key as splitPk because it is usually evenly distributed, thus the resulting partitions are less likely to have data hotspots.
Currently, splitPk only supports partitioning integer data, not strings, floating points, or dates. If you specify an unsupported type, the splitPk feature will be ignored, and single-channel synchronization will be used.
If the splitPk value is set to empty, it is considered that partitioning for a single table is not allowed, so single-channel extraction will be used.
Filter Conditions (Optional)
Fill in the corresponding filter statements according to the data type. This statement will be used as the filter condition for the data to be synchronized.
GBase splices SQL according to the specified where condition and extracts data based on that SQL. For example, during testing, you can specify the where condition as limit 10. In actual business scenarios, you would typically select the data of the current day for synchronization, specifying the where condition as gmt_create > $bizdate.
The where condition can effectively perform incremental business synchronization.
If the where condition is empty, it is considered that the entire table's information will be synchronized.
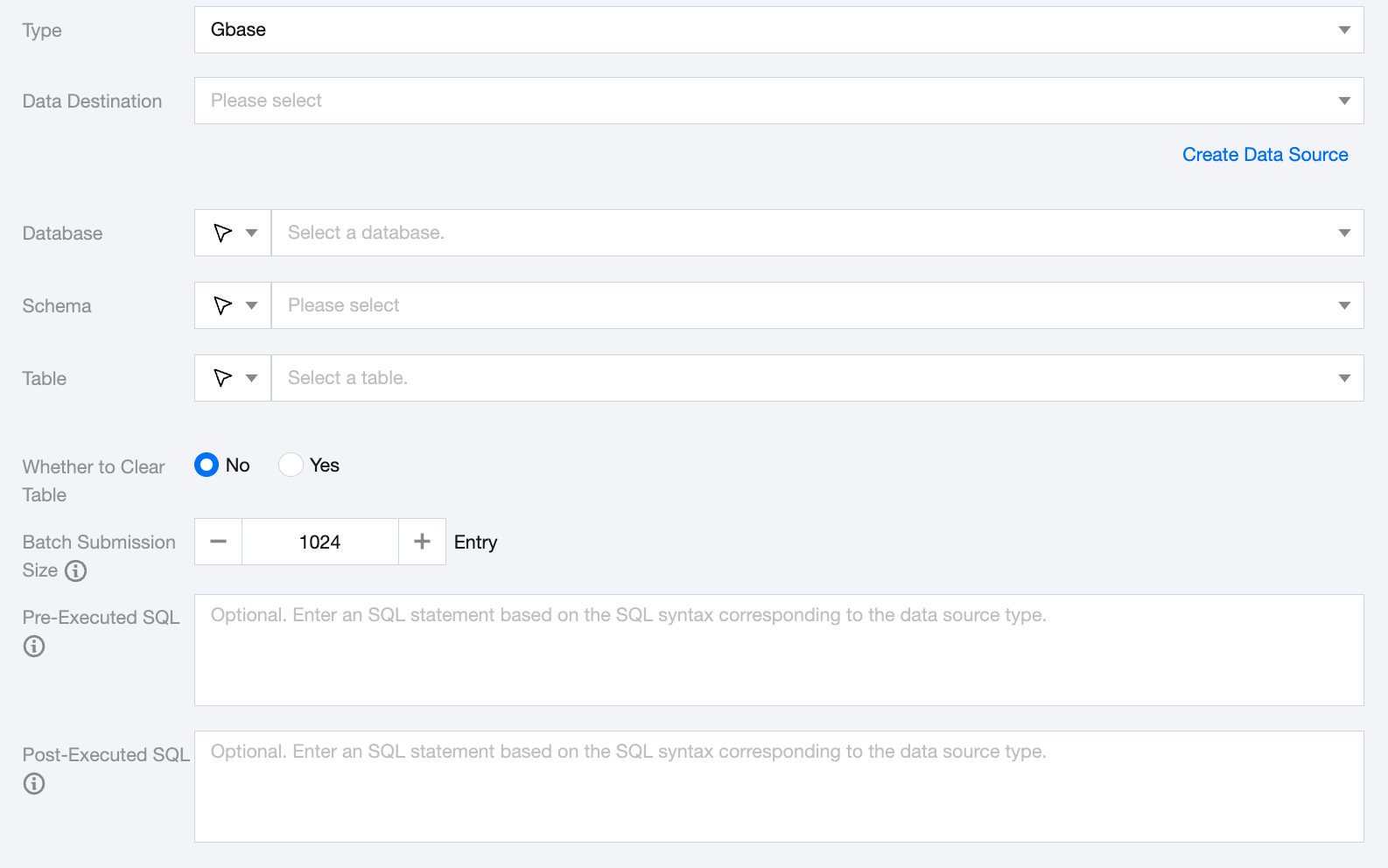
GBase Offline Single Table Write Node Configuration
Parameters
Description
Data Destination
GBase Data Source to be written.
Database
Supports selection or manual input of the database name to write to
By default, the database bound to the data source is used as the default database. Other databases need to be manually entered.
If the data source network is not connected and the database information cannot be fetched directly, you can manually enter the database name. Data synchronization can still be performed when the Data Integration network is connected.
Schema
Supports selection or manual input of the Schema name to be read.
Table
Supports selection or manual input of the table name to write to
If the data source network is not connected and the table information cannot be fetched directly, you can manually enter the table name. Data synchronization can still be performed when the Data Integration network is connected.
When the source table is of Oracle type, GBase supports one-click creation of the target table.
Whether to Clear Table
Before writing to the GBase data table, you can manually choose whether to clear the data table.
Batch Submission Size
The record size for Batch Submission can greatly reduce the Number of Network Interactions between the Data Synchronization system and GBase, thereby improving overall Throughput. If this value is set too high, it may cause OOM exceptions in the Data Synchronization process.
Pre-Executed SQL (Optional)
The SQL statement executed before the synchronization task. Fill in the correct SQL syntax according to the data source type, such as clearing the old data in the table before execution (truncate table tablename).
Post-Executed SQL (Optional)
The SQL statement executed after the synchronization task. Fill in the correct SQL syntax according to the data source type, such as adding a timestamp (alter table tablename add colname timestamp DEFAULT CURRENT_TIMESTAMP ON UPDATE CURRENT_TIMESTAMP).