Batch creation of periodic single table tasks supports over 30 relational data sources, enhancing task configuration efficiency.
Conditions and Restrictions
1. The source and target data sources have been configured for subsequent tasks.
2. The DataInLong Resource Group has been purchased.
3. Network connectivity between the DataInLong Resource Group and the data source has been completed.
4. The data source environment preparation has been completed. Based on the sync configuration you need, grant the data source configuration account the necessary operation permissions in the database before executing the sync task.
5. If the database account configured for the data source lacks read and write permissions, it will cause the task to fail. Please configure an account with appropriate permissions according to the actual read and write scenarios.
Step 1: Create a bulk single table synchronization task
2. click on Project List in the left menu and find the target project you need to operate.
3. After selecting a project, click to enter the DataInLong module.
4. click Offline Synchronization > Batch Create Single Table Synchronization Tasks in the menu on the left.
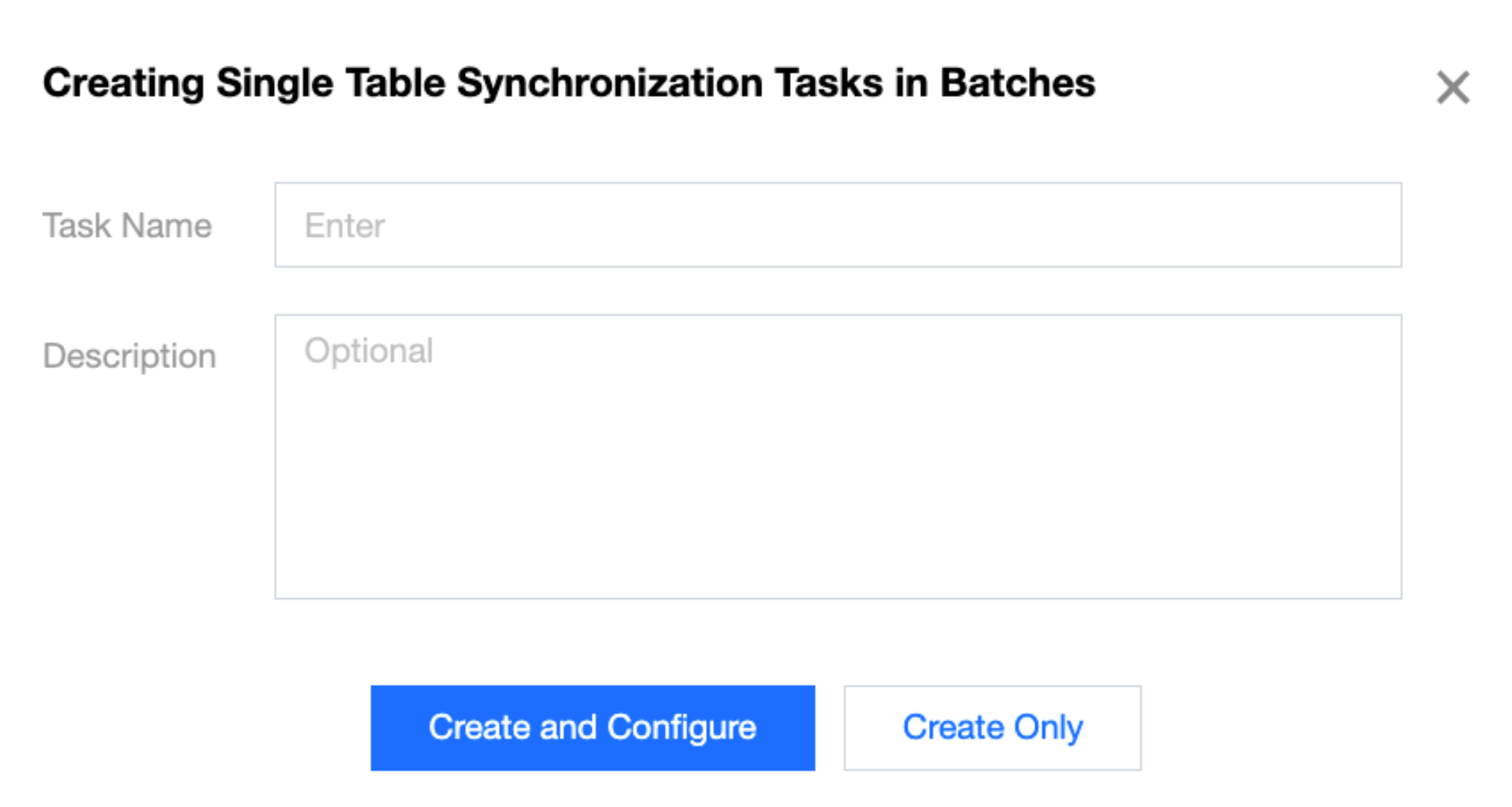
5. After clicking Create, you will enter the configuration page for batch creation of single table synchronization tasks. Fill in the task name and description, then click Create and Configure.
Parameter
Description
Task Name
Task Name.
Description
Optional.
Step 2: Data node configuration
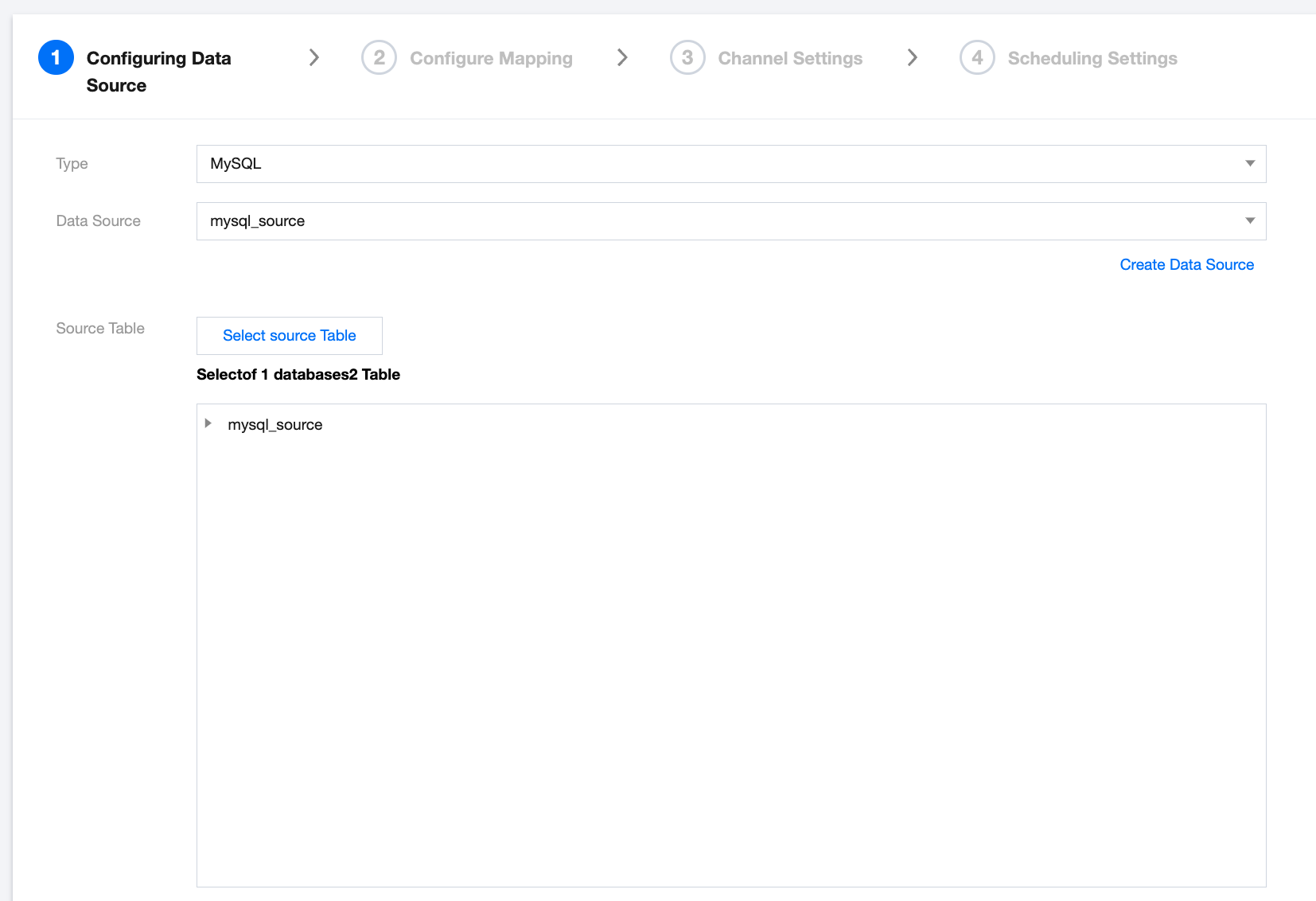
Read Node
Read node general configuration includes type, data source, source table, etc.
Parameter
Description
Data Source Type
Select Data Source Type
Data Source
Select an available data source under the selected data source type.
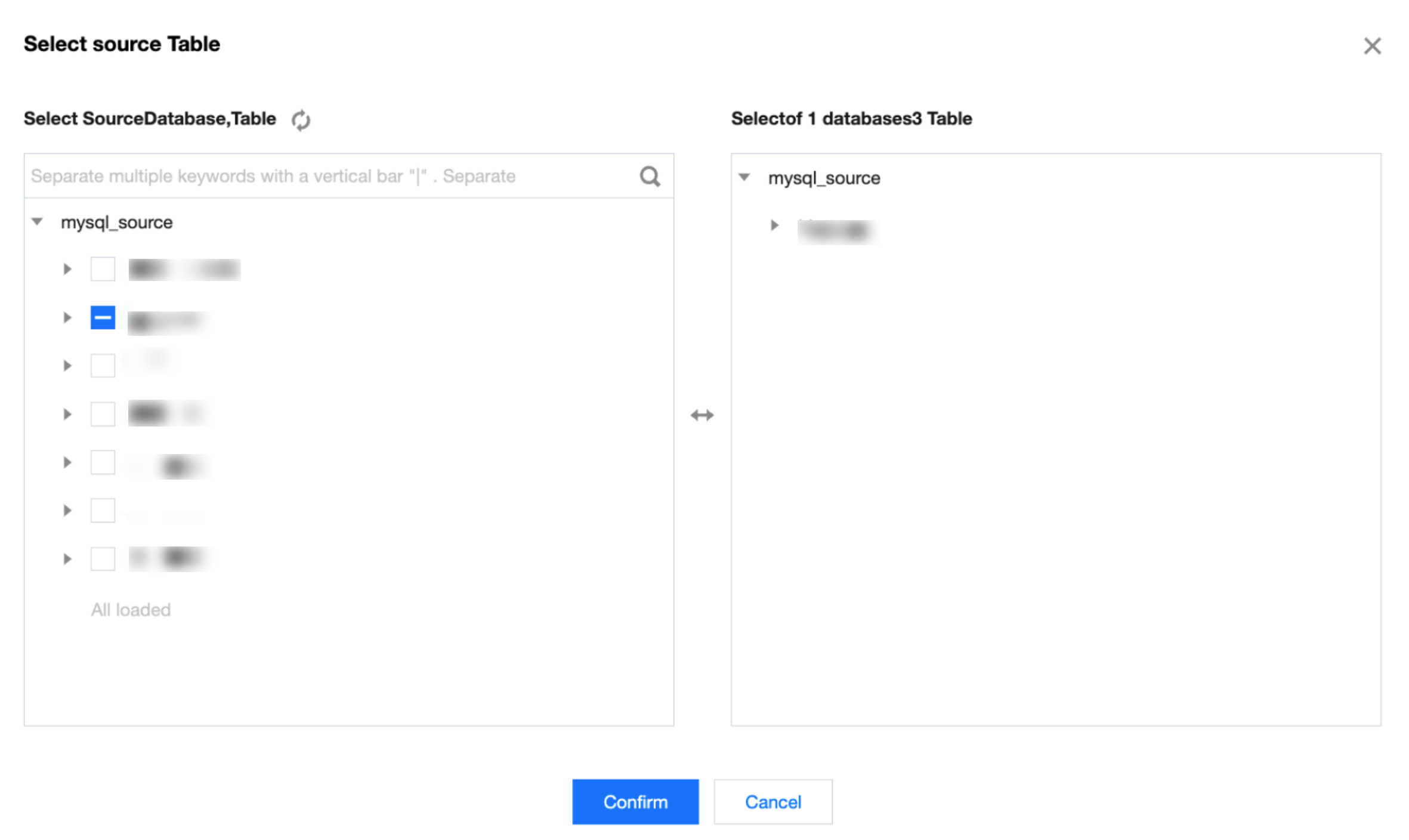
Source Table
Select Source Repository, Table
Note:
The maximum number of single batch tasks supported by a source table is 500 tables
Other Configuration Items
Refer to the configuration method of the specific data source. See the data sources supported by Offline Synchronization.
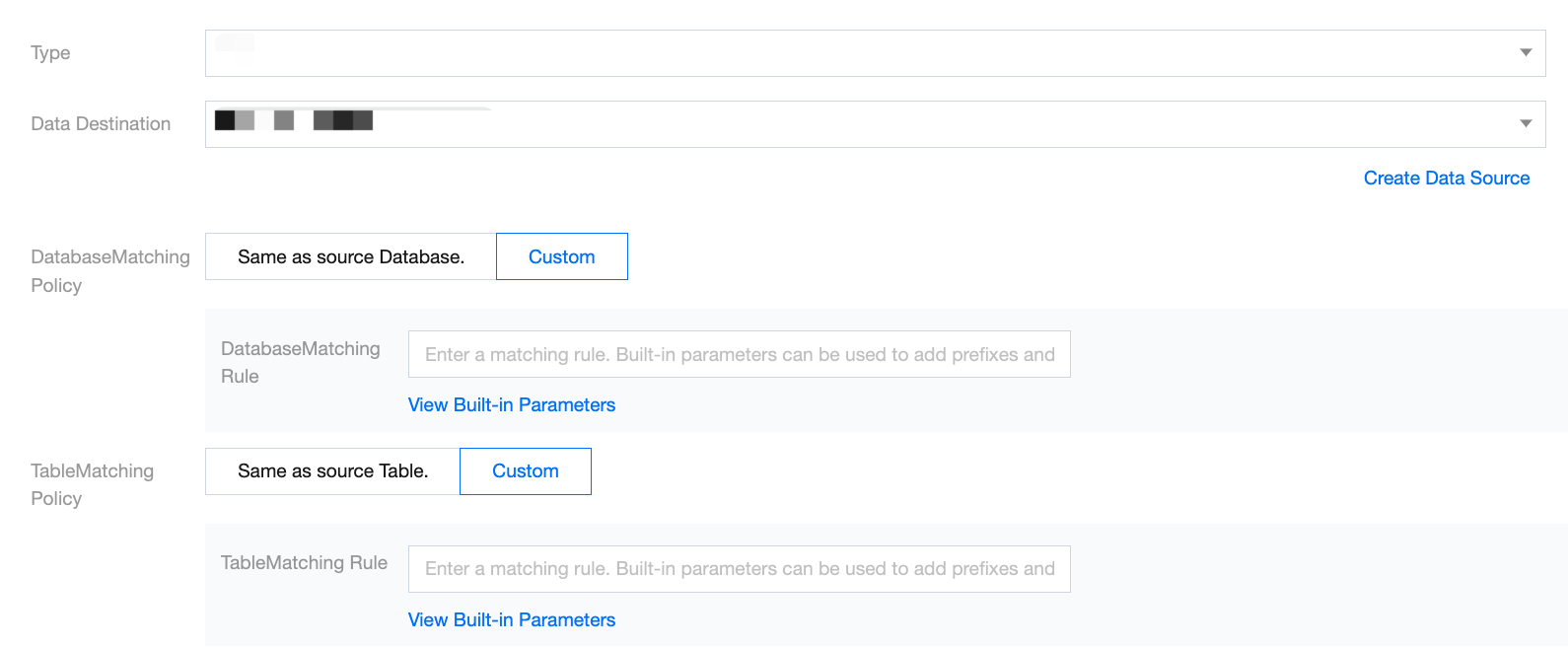
Write Node
Write Node General Configuration includes type, data destination, database matching strategy, table matching strategy, etc.
Parameter
Description
Data Source Type
Select Data Source Type
Data Destination
Select an available data source under the selected data source type to write to.
Database Matching Policy
Same name as Source Database: Matches the database name selected in the read node.
Custom: Input matching rules, supporting the use of built-in parameters and strings to generate target database names.
Table Matching Policy
Same name as Source Table: Matches the table name selected in the read node.
Custom: Input matching rules, supporting the use of built-in parameters and strings to generate target table names.
Other Configuration Items
Refer to the configuration method of the specific data source. See the data sources supported by Offline Synchronization.
Case 1: Database - Database Link Configuration Mapping Relationship
Parameter
Description
Serial Number
Sort in ascending order and display the mapping relationship list number.
Source Database
The database selected in the data node configuration read end.
Source Table
The data table selected by the reading end in the data node configuration.
Target Database
The database selected by the writing end in the data node configuration. Supports Input Mode and Selection Mode.
Target Table
The data table selected by the writing end in the data node configuration. Supports Input Mode and Selection Mode.
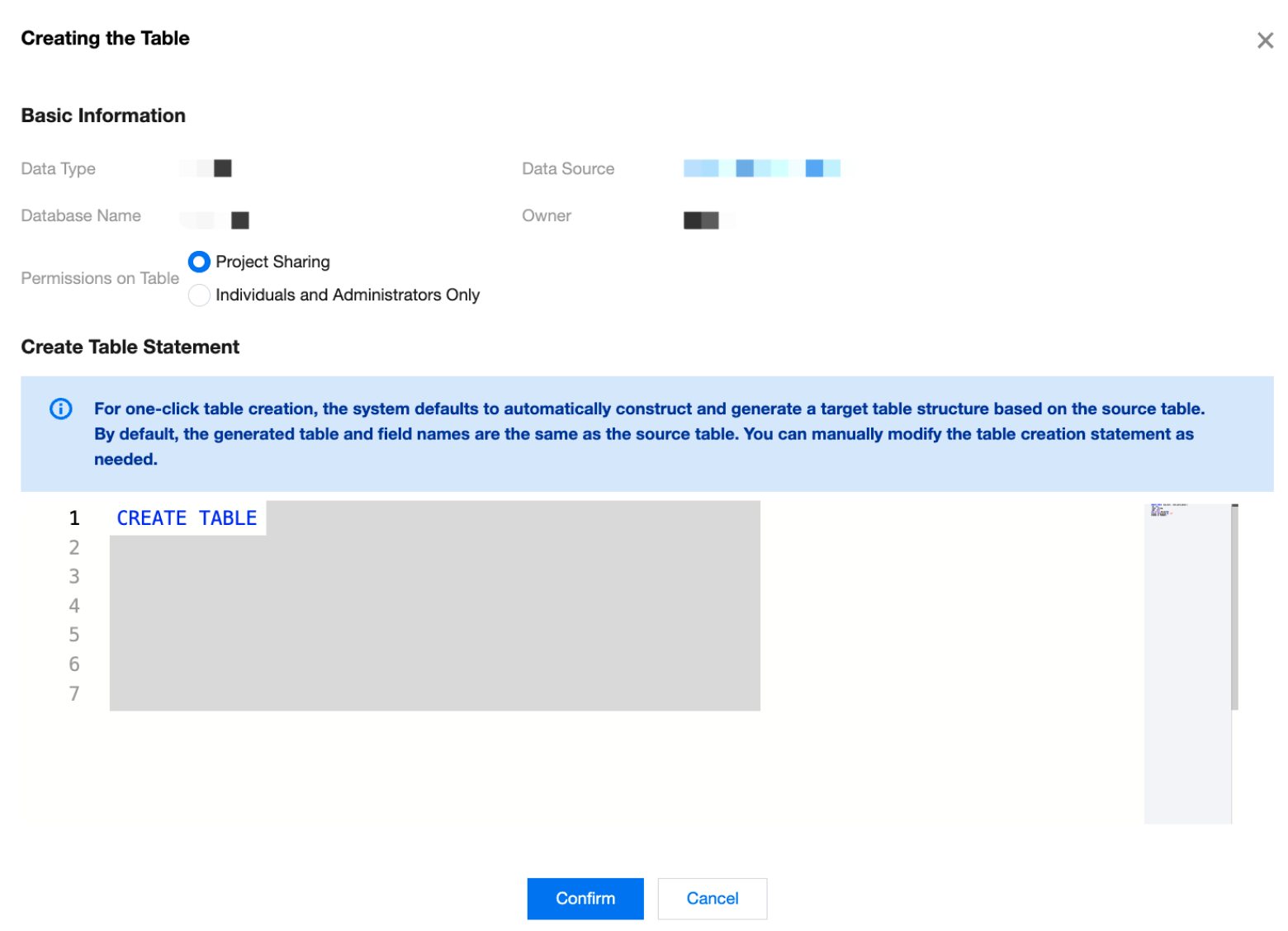
Create
Create the data table for the writing end, automatically building the target table structure based on the source table, and support manual modification of key table statements.
Note:
The following links support the creation of data tables for the writing end:
The field mapping relationship aims to designate the source of the target field content through connecting lines, supporting Mapping by the same name and Peer Mapping. Customized field mapping rules are supported by editing tasks.
Configure Resource Group
Supports selecting available resource groups from a drop-down menu.
Operation
Editing Task
Supports detailed personalized configurations, such as configuring data sources, field mapping rules, etc.
Remove
Delete this row mapping relationship.
Creating Target Tables in Batches
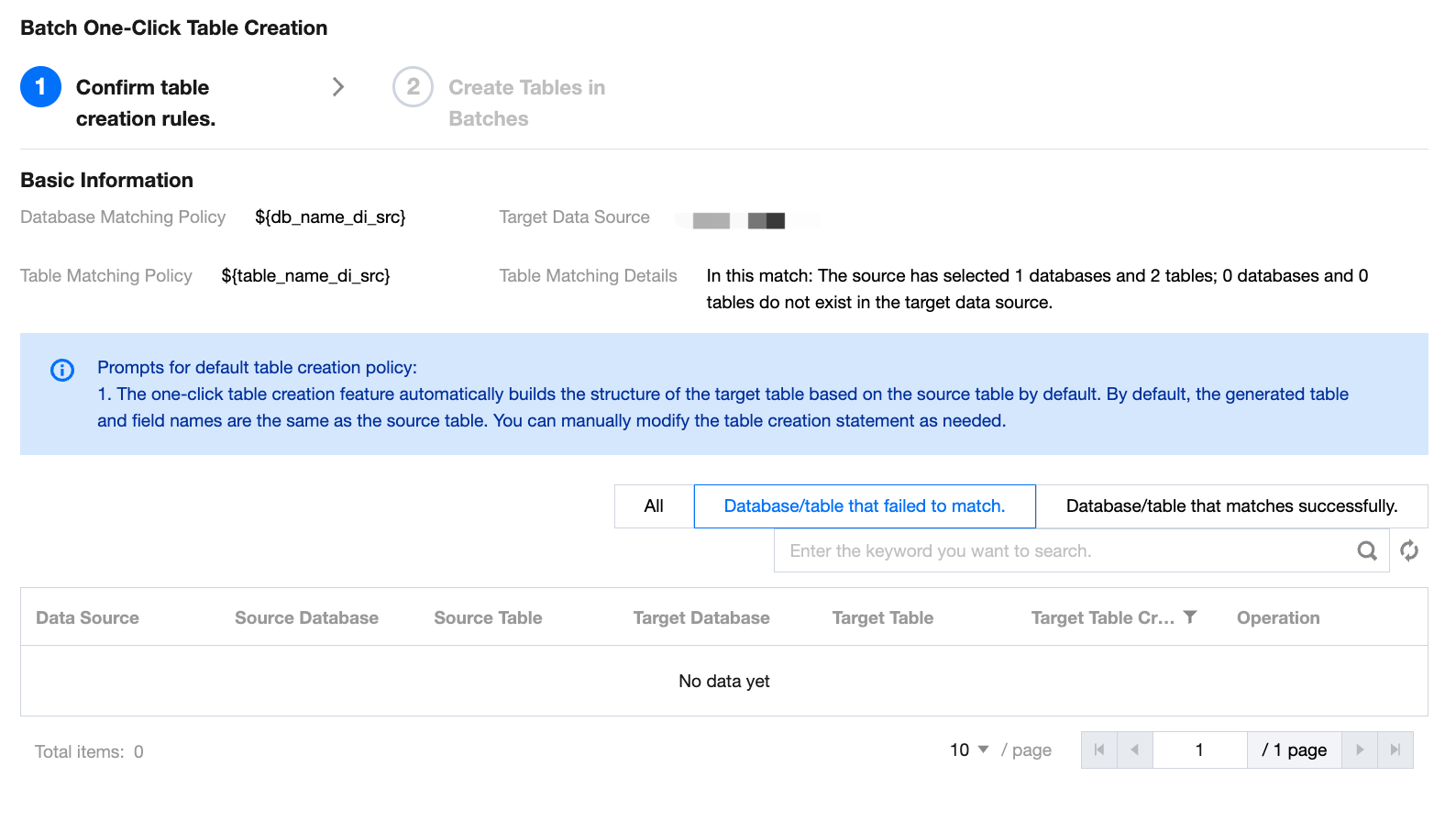
After selecting the list, you can batch create data tables for the writing end.
Confirm table creation rules: Confirm key table information such as data source and source repository. Supports previewing/editing table statements.
Create Tables in Batches: Display key table results, support viewing key table statements, and retry.
Configure Field Mapping Rules Batches
After selecting the list, batch configuration of mapping relationships is supported. You can choose Mapping by the same name or Peer Mapping.
Configure Resource Groups in Batches
After selecting from the list, batch configuration of available resource groups is supported.
Batch Remove
After selecting from the list, batch deletion of selected mapping relationships is supported.
Scenario Two: File to File Link Configuration Mapping Relationship
Parameter
Description
Serial Number
Sort in ascending order and display the mapping relationship list number.
Source file path
When the reader is FTP, SFTP, HDFS, or S3, manual entry is required.
When the reader is COS, manual input or selection mode is supported.
Target file path
When the writer is FTP, SFTP, HDFS, or S3, manual entry is required.
When the writer is COS, manual input or selection mode is supported.
Field Mapping Rules
The field mapping relationship aims to designate the source of the target field content through connecting lines, supporting Mapping by the same name and Peer Mapping. Customized field mapping rules are supported by editing tasks.
Configure Resource Group
Supports selecting available resource groups from a drop-down menu.
Operation
Editing Task
Supports detailed personalized configurations, such as configuring data sources, field mapping rules, etc.
Remove
Delete this row mapping relationship.
Configure Field Mapping Rules Batches
After selecting the list, batch configuration of mapping relationships is supported. You can choose Mapping by the same name or Peer Mapping.
Configure Resource Groups in Batches
After selecting from the list, batch configuration of available resource groups is supported.
Batch Remove
After selecting from the list, batch deletion of selected mapping relationships is supported.
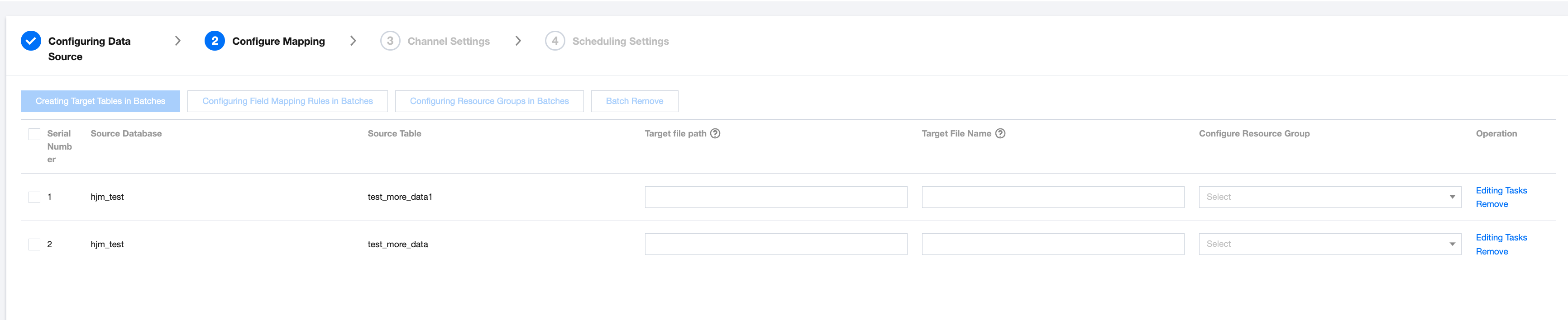
Scenario 3: Database-File Link Configuration Mapping Relationship
Parameter
Description
Serial Number
Sort in ascending order and display the mapping relationship list number.
Source Database
The database selected in the data node configuration read end.
Source Table
The data table selected by the reading end in the data node configuration.
Target file path
When the writer is FTP, SFTP, HDFS, or S3, manual entry is required.
When the writer is COS, manual input or selection mode is supported.
Target File Name
When the writer is FTP, SFTP, HDFS, or S3, manual entry is required by the user.
When the writer is COS, manual input or selection mode is supported.
Field Mapping Rules
The field mapping relationship aims to designate the source of the target field content through connecting lines, supporting Mapping by the same name and Peer Mapping. Customized field mapping rules are supported by editing tasks.
Configure Resource Group
Supports selecting available resource groups from a drop-down menu.
Operation
Editing Task
Supports detailed personalized configurations, such as configuring data sources, field mapping rules, etc.
Remove
Delete this row mapping relationship.
Configure Field Mapping Rules Batches
After selecting the list, batch configuration of mapping relationships is supported. You can choose Mapping by the same name or Peer Mapping.
Configure Resource Groups in Batches
After selecting from the list, batch configuration of available resource groups is supported.
Batch Remove
After selecting from the list, batch deletion of selected mapping relationships is supported.
Scenario 4: File - Database Link Configuration Mapping Relationship
Parameter
Description
Serial Number
Sort in ascending order and display the mapping relationship list number.
Source file path
When the reader is FTP, SFTP, HDFS, or S3, manual entry is required.
When the reader is COS, manual input or selection mode is supported.
Target Database
The database selected by the writing end in the data node configuration. Supports Input Mode and Selection Mode.
Target Table
The data table selected by the writing end in the data node configuration. Supports Input Mode and Selection Mode.
Field Mapping Rules
The field mapping relationship aims to designate the source of the target field content through connecting lines, supporting Mapping by the same name and Peer Mapping. Customized field mapping rules are supported by editing tasks.
Configure Resource Group
Supports selecting available resource groups from a drop-down menu.
Operation
Editing Task
Supports detailed personalized configurations, such as configuring data sources, field mapping rules, etc.
Remove
Delete this row mapping relationship.
Configure Field Mapping Rules Batches
After selecting the list, batch configuration of mapping relationships is supported. You can choose Mapping by the same name or Peer Mapping.
Configure Resource Groups in Batches
After selecting from the list, batch configuration of available resource groups is supported.
Batch Remove
After selecting from the list, batch deletion of selected mapping relationships is supported.
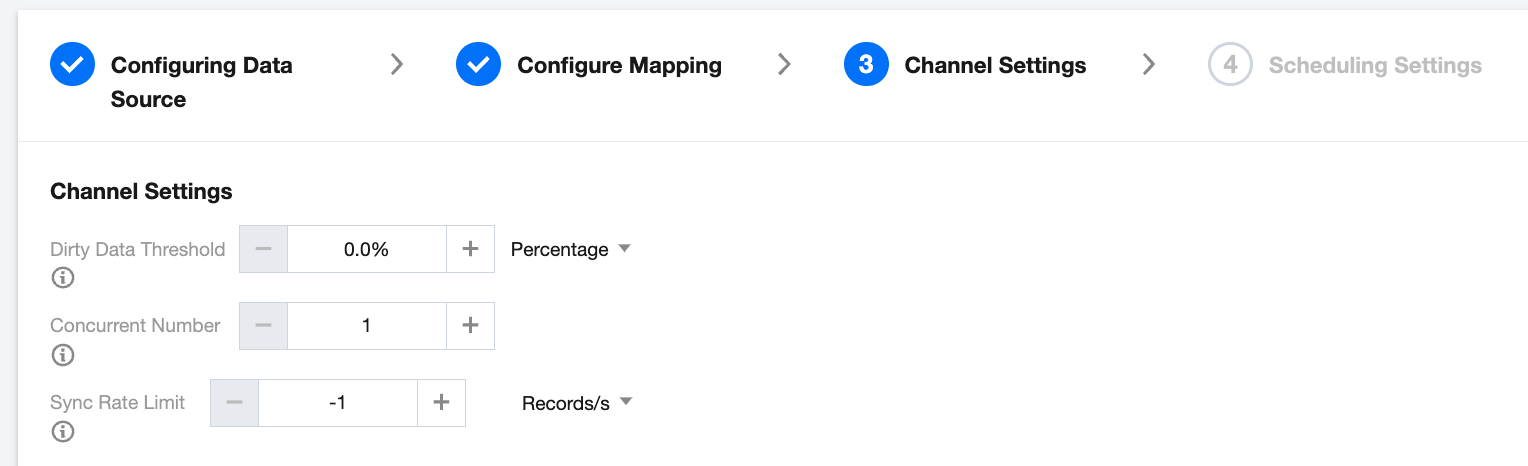
Step 4: Channel Settings
Parameter
Description
Dirty Data Threshold
Dirty data refers to data that failed to be written during synchronization. The dirty data threshold is the maximum number of dirty data records tolerated during synchronization. Once this threshold is exceeded, the task will terminate automatically. The default threshold is 0, meaning dirty data is not tolerated.
Concurrency Number
The maximum number of concurrent operations expected during actual execution. Due to resources, data source types, and task optimization results, the actual number of concurrent operations may be less than or equal to this value. The larger this value is, the more pre-allocated execution machine resources.
Sync Rate Limit
Limit the synchronization rate by traffic or number of records to protect the read and write pressure on the data source endpoint or data destination endpoint. This value is the maximum operating rate, with the default -1 indicating no rate limit.
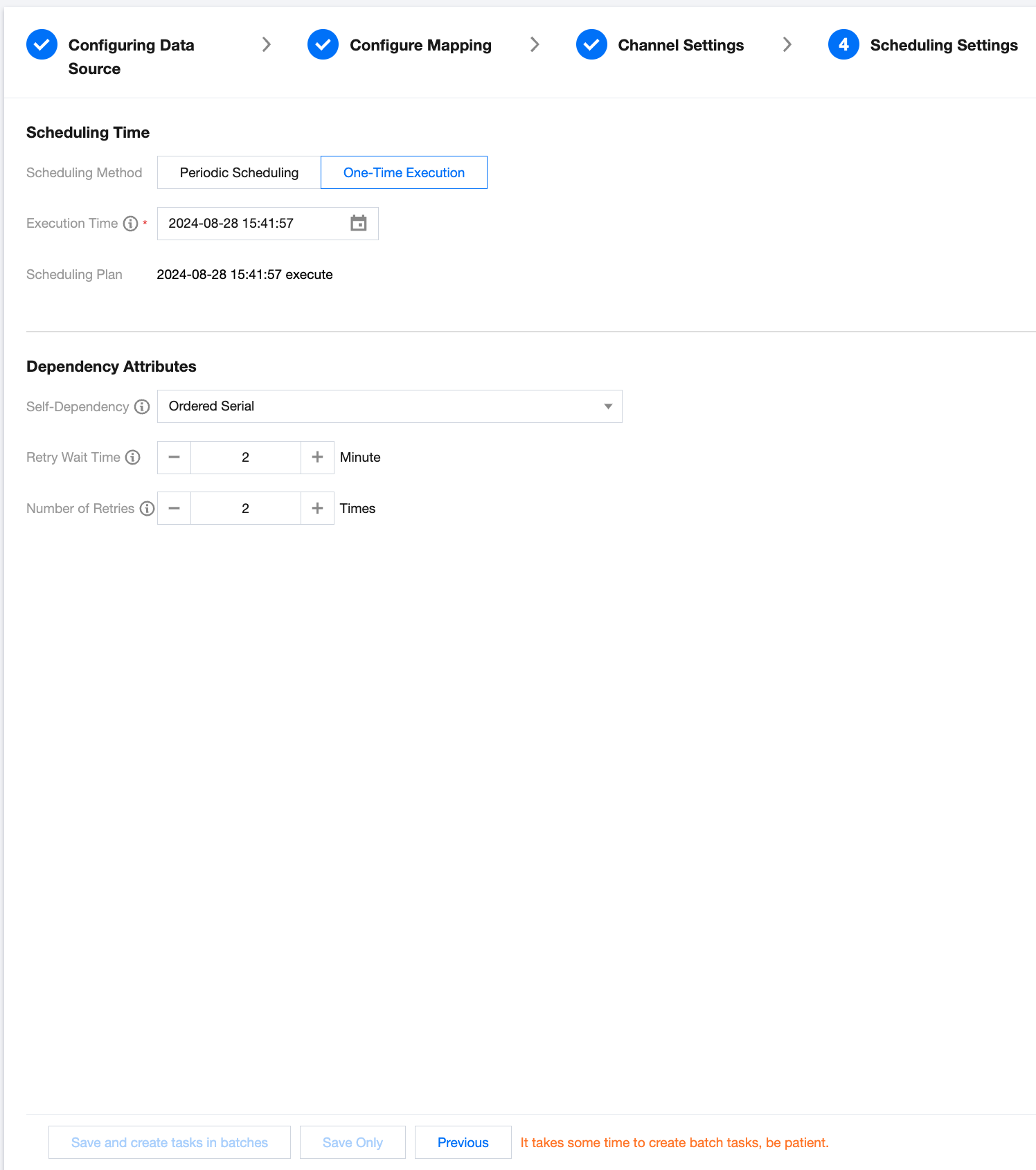
Step 5: Scheduling Settings
Category
Parameter
Description
Scheduling Time
Scheduling Method
Periodic Scheduling: The task runs cyclically according to the scheduled plan.
One-time Execution: The task runs only once at the specified time.
Effective Date
The valid time period for scheduling time configuration. The system will automatically schedule within this time range according to the time configuration, and will no longer automatically schedule after the validity period.
Scheduling Cycle
Interval step unit for scheduling plans, supports Year, Month, Weekly, Days, Hour, Minutes:
minutes: You need to specify the exact execution start time and interval. The task will run at the fractional start time of every hour according to the specified interval. For example, if the execution time is from 02:00 to 23:59 with an interval of 5 minutes, the task will run every 5 minutes starting from 02:00.
Hour: Requires specifying specific execution start and end times and interval. For example, if the execution time is from 02:20 to 05:00, with an interval of 1 hour, then the task will run at 02:20, 03:20, and 04:20 respectively.
Days: Requires specifying the specific execution time each day. The task will run only at that time every day.
Weekly: Requires specifying the day(s) of the week for a fixed run (multiple selections supported) and the time. The task runs only at the specified time on the designated day.
Month: Specify the fixed monthly run number and time. If the end of the month is selected, the last day of each month will be used for the run.
Year: Specify the fixed annual run date and time.
Scheduling plan
Plan generated based on configuration results.
Cron Expression
Expression generated based on configuration results.
Dependency Attributes
Self-Dependency
Self-Dependency refers to the dependency relationship between different instances within the same task:
Ordered Serialization: The current instance depends on the status of the previous cycle instance.
Unordered Serial: The current instance and the previous cycle instance have no dependency relationship. If a task has multiple instances at the same time, the system randomly selects an instance to run. Only one instance is in a running state at the same time.
Parallel: There is no dependency relationship between the previous and subsequent cycle instances. If a task has multiple instances at the same time, multiple instances will run simultaneously.
Retry Wait Time
Maximum waiting time interval for each retry after an instance fails. If the instance has not been retried after exceeding this value, it will be marked as failed.
Number of Retries
Maximum number of retries after an instance fails. If this value is exceeded, the task will be marked as failed.
Save and create tasks in batches
Generate the bulk task creation itself, and start creating single table synchronization tasks.
Save Only
Generate the bulk task creation itself, but do not start creating single table synchronization tasks.
Step 6: View the generated bulk single table synchronization tasks
Parameter
Description
Task Name
User-defined Task Names.
Source
Name of the data source selected by the reading end.
Target
Name of the data source selected by the writing end.
Total Tasks
Total number of single table tasks in the bulk task.
Successful Tasks
Displays the number of successfully created single table tasks (refreshes every 60 seconds). Click to view specific task details.
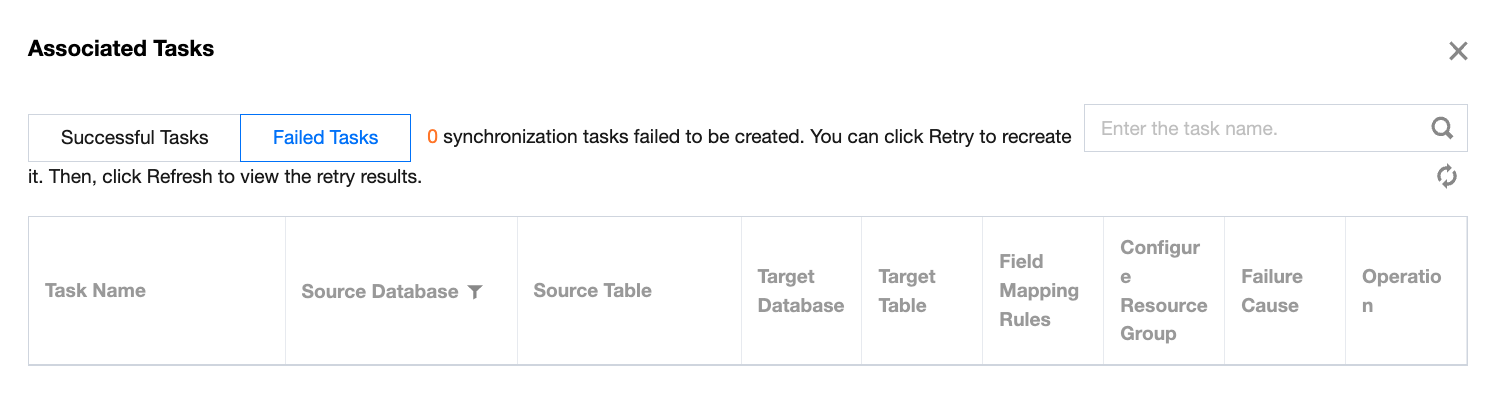
Failed Tasks
Displays the number of failed single table tasks (refreshes every 60 seconds). Click to view specific task details and retry options.
Created by
Batch task creator username.
Task Status
The current status of the task, including initialization, creating, completed, terminating, terminated.
Start Time
Time when batch single table task creation started.
End time
Time when batch single table task creation was completed.
Operation
Start Creating
Start creating batch single table tasks.
Force Termination
Force terminate the ongoing batch task creation. After termination, created tasks will not be rolled back, and incomplete tasks will not be created. Uncompleted tasks are counted in the number of failed tasks.
Delete
Delete unstarted or completed batch single table tasks.