DataInLong provides reading and writing capabilities for PostgreSQL. This document introduces the pre-environment configuration for real-time data synchronization using PostgreSQL and the current capability support situation.
Supported Versions
Currently, DataInLong supports real-time reading and writing for both single table and full database levels in PostgreSQL. To use real-time synchronization, the following version restrictions must be followed:
Data Source Type
Edition
PostgreSQL
Version 9.6 or above
Use Limits
A PostgreSQL data source can only correspond to one database. Therefore, a real-time full database task only supports synchronizing tables within one database, and cross-database table selection is not supported.
Tables without primary keys may have data duplication since exactly once cannot be guaranteed. Therefore, it is best to ensure the table has a primary key for real-time sync tasks.
Schema changes on the PostgreSQL source depend on data transmission. Schema changes can only be detected when there is data being sent after the schema change.
Renaming a column on the PostgreSQL source will be recognized as deleting the column and adding a new column
Deleting or emptying tables on the PostgreSQL source cannot be synchronized to the target end. Such changes are ignored by default.
Preparing the Database Environment
1. Modify postgres.conf and enable wal:
wal_level = logical
2. Enable full replication for the tables that need to be synchronized:
ALTERTABLE<table> REPLICA IDENTITYFULL;
3. Required permissions: (replace my_ prefixes with actual database, schema, table, username)
GRANTCONNECTONDATABASE my_db TO my_user;
GRANTUSAGEONSCHEMA my_schema TO my_user;
GRANTSELECTONALLTABLESINSCHEMA my_schema TO my_user;
ALTERUSER my_user REPLICATION;
GRANTCREATEONDATABASE my_db TO my_user;
4. You can skip the following permissions by pre-creating a pg_publication named dbz_publication:
GRANTCREATEONDATABASE my_db TO my_user;
Database source configuration
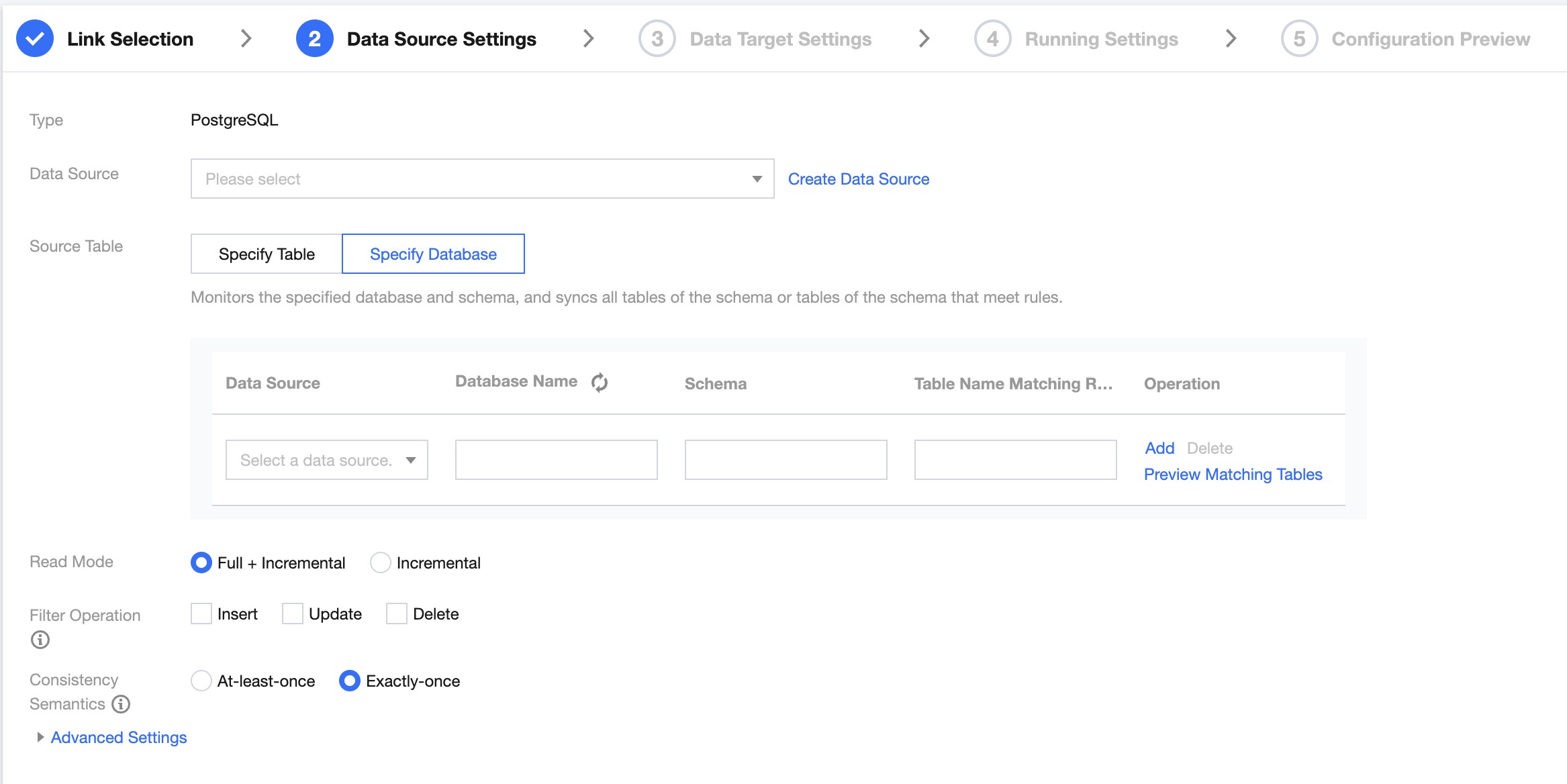
Data source settings
Parameter
Description
Data Source
Select the PostgreSQL data source that needs to be synchronized.
Source Table
PostgreSQL only supports specifying tables and databases, not all databases and tables:
Specify Table: Under this option, you need to specify the exact table name. Once set, the task will only synchronize the specified table and can only select tables within one database; cross-database selection is not supported. If you need to add more tables for synchronization, you must pause and restart the task.
Specify Database: Under this option, you need to specify the exact database name and a table name regular expression. The database name must be the same, and multiple databases are not supported. Once set, the newly added tables that match the table name expression will be synchronized to the target during task operation.
Read Mode
Full + Increment: Data synchronization is divided into full and increment phases. After the full phase is completed, the task enters the increment phase. The full phase will synchronize historical data in the database, and the incremental phase starts synchronizing from the binlog cdc location after the task starts.
Increment: Synchronize data only from the binlog cdc location after the task starts.
Time Zone
Set the timezone for log time, default is Shanghai.
Filter Operation
Supports three operations: insert, update, and delete. Data of the specified operation type will not be synchronized when set.
Consistency Semantics
Only represents the consistency semantics of the reading end. Supports At-least-once and Exactly-once.
At-least-once: Data may be read more than once, relying on the destination end's deduplication to ensure data consistency. Suitable for scenarios with large data volumes in the full phase and using non-numeric primary keys, with high synchronization performance requirements.
Exactly-once: Data is read strictly once, with some performance losses. Tables without a primary key and unique index column are not supported. Suitable for general scenarios where the source table has a numeric primary key or unique index column.
The current version's two modes are state-incompatible. If the mode is changed after task submission, stateful restart is not supported.
Advanced Settings (optional)
You can configure parameters according to business needs.
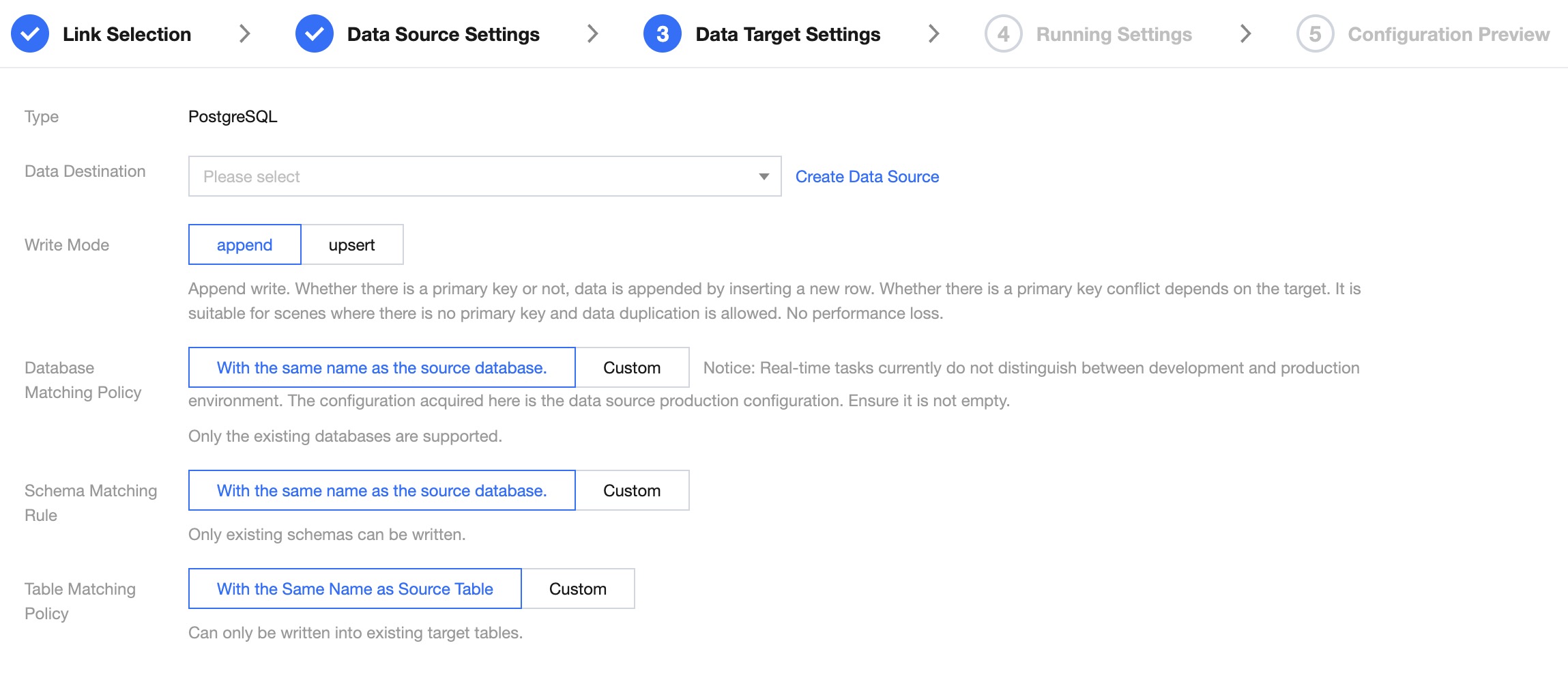
Whole Database Writing Configuration
Parameter
Description
Data Destination
Select the PostgreSQL target data source to be synchronized.
Write Mode
Upsert: Update method to write to the target table. This method requires that the target table has a primary key set. The task will use the primary key as the unique key to update records by default.
If the table has no primary key, it will use Append to write.
Append: Append mode to write to the data table.
Database/Schema/Table Matching Policy
By default, it has the same name as the source database/table. You can also configure it via Definition, just enter the matching rules (hover over "View Built-in Parameters" to see the matching rules).
PostgreSQL target temporarily does not support automatic database/Schema/table creation. It only supports synchronization to existing databases, schemas, and tables. Ensure that the target table exists before running the task.
Note:
Currently, only MySQL type data can be synchronized in full database mode to PostgreSQL.
Single Table Read Node Configuration
1. In the DataInLong page, click Real-time synchronization on the left directory bar.
2. In the real-time synchronization page, select Single Table Synchronization at the top to create a new one (you can choose either form or canvas mode) and enter the configuration page.
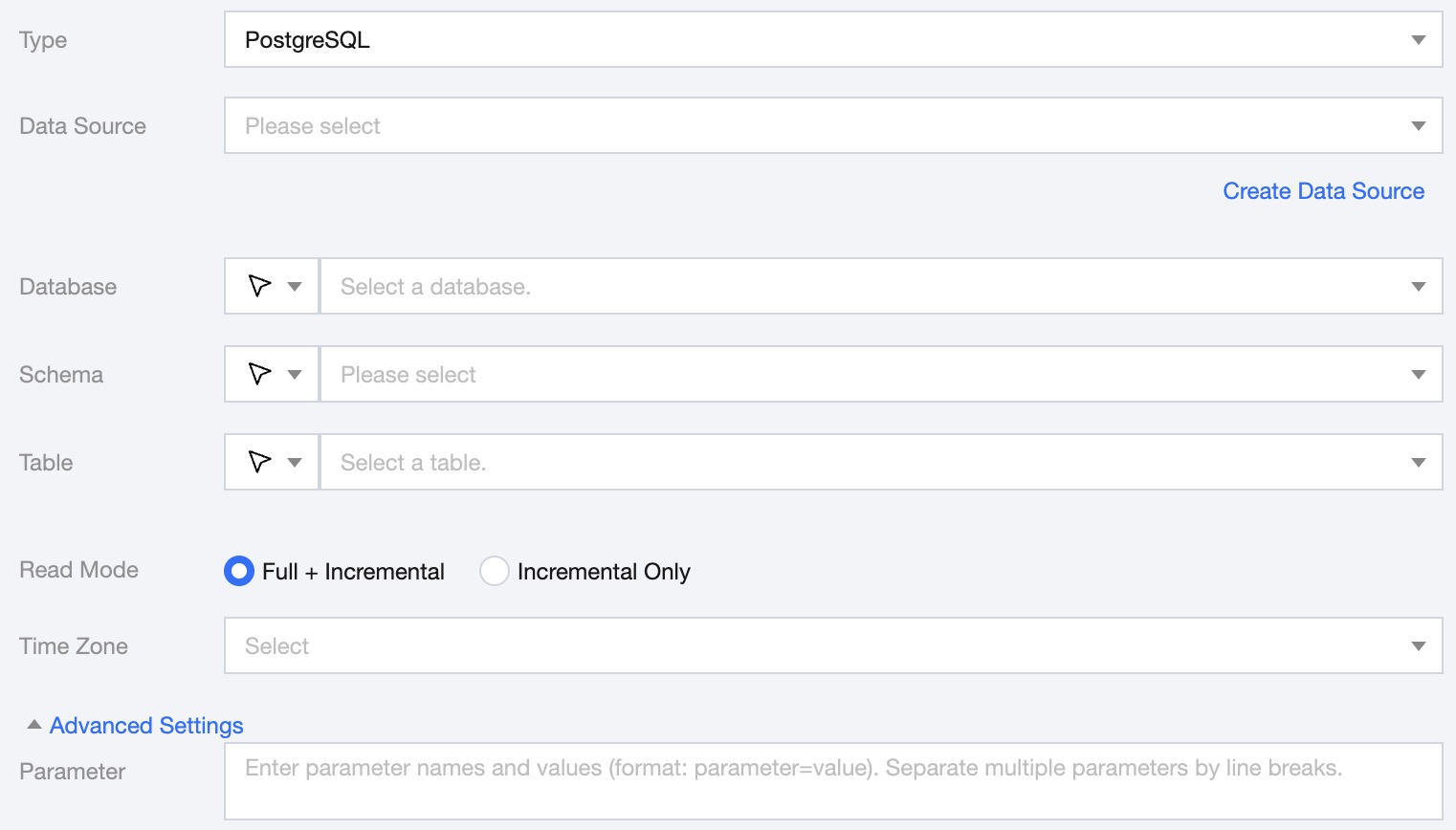
Parameter
Description
Data Source
Select the data source where the table to be synchronized is located.
Database
Supports selection or manual input of the library name to read from.
By default, the database bound to the data source is used as the default database. Other databases need to be manually entered.
If the data source network is not connected and the database information cannot be fetched directly, you can manually enter the database name. Data synchronization can still be performed when the Data Integration network is connected.
Schema
Supports selecting or manually entering the available schema under the data source to be read.
Table
Supports selecting or manually entering the table name to be read.
Read Mode
Full + Increment: Data synchronization is divided into full and increment phases. After the full phase is completed, the task enters the increment phase. The full phase will synchronize historical data in the database, and the incremental phase starts synchronizing from the binlog cdc location after the task starts.
Increment Only: Only synchronize data from the binlog cdc position after the task starts.
Advanced Settings (Optional)
You can configure parameters according to business needs.
Single Table Writing Node Configuration
1. In the DataInLong page, click Real-time synchronization on the left directory bar.
2. In the real-time synchronization page, select Single Table Synchronization at the top to create a new one (you can choose either form or canvas mode) and enter the configuration page.
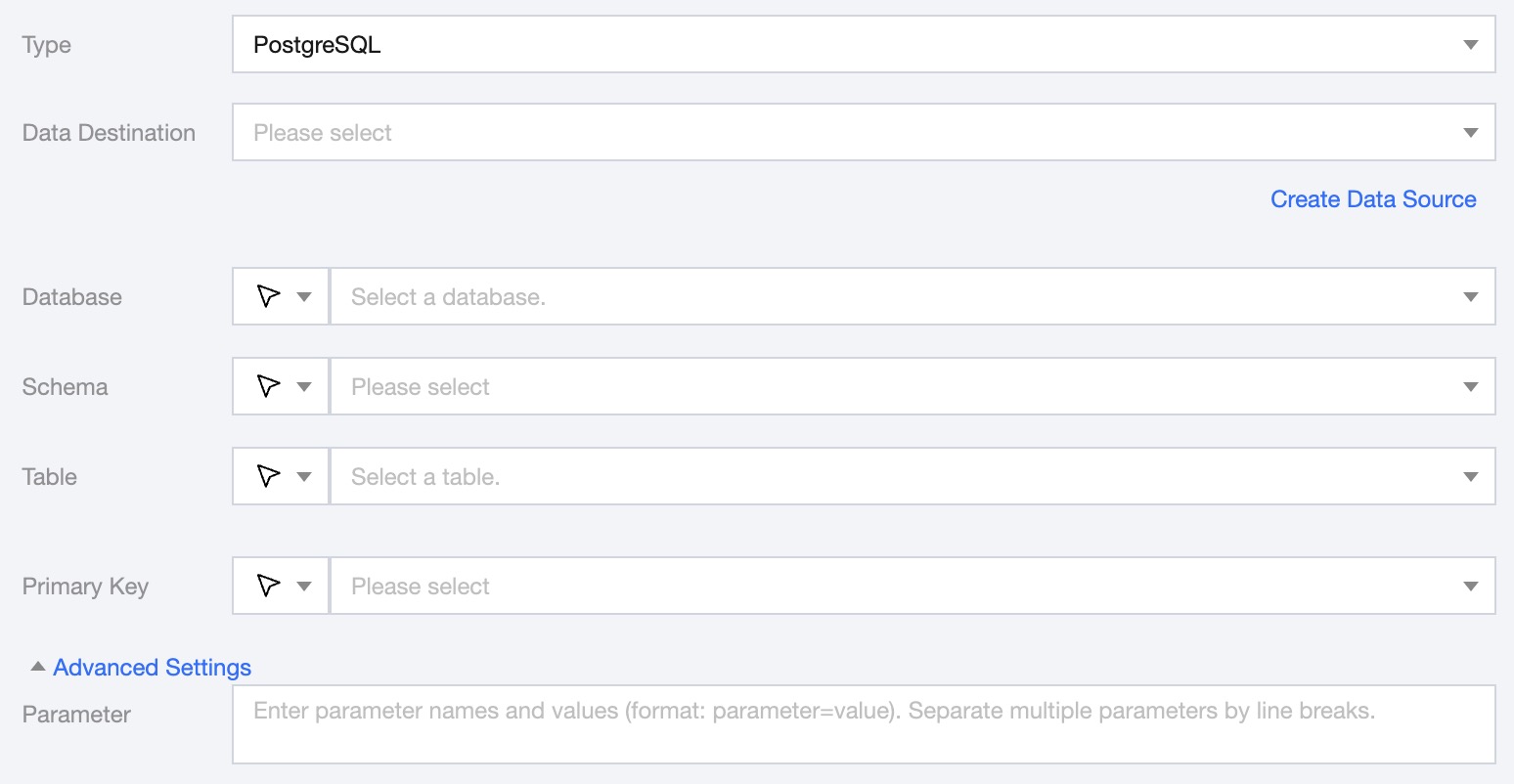
Parameter
Description
Data Destination
Select the data source where the table to be written is located.
Database
Support selection or manual entry of the library name to be written to.
By default, the database bound to the data source is used as the default database. Other databases need to be manually entered.
If the data source network is not connected and the database information cannot be fetched directly, you can manually enter the database name. Data synchronization can still be performed when the Data Integration network is connected.
Schema
Supports selecting or manually entering the available schema under the data source to be written.
Table
Supports selecting or manually entering the table name to be written.
Primary key
Select a field as the primary key for the target table.
Advanced Settings (Optional)
You can configure parameters according to business needs.
Log collection write node configuration
Parameter
Description
Data Destination
Select the available PostgreSQL data source in the current project.
Database/Table
Select the corresponding database table in the PostgreSQL data source.
Mode
Select the schema in the PostgreSQL data source.
Primary key
Select a field as the primary key for the data table
Advanced Settings (optional)
You can configure parameters according to business needs.
Data type conversion support
Read
The data types and conversion relationships supported by PostgreSQL for reading are as follows: