Currently, WeData supports the following Data Source Types:
EMR
EMR-Hive
DLC
TCHouse-P
TCHouse-D
Doris
Ways to Add Monitoring Rules
Currently, WeData supports the following three methods:
Add Rules for a Single Table: Create monitoring rules for the same table.
Only one table can be selected at a time.
Multiple rules can be added at a time.
Add Rules to Multiple Tables: Batch create monitoring rules for multiple fields of multiple tables in the same data source.
Multiple tables and multiple fields can be selected at a time.
Only one monitoring rule can be selected at a time.
Batch Upload Rules: Upload an Excel template for bulk import.
Only one data source type can be selected at a time.
Only supports custom SQL (does not support built-in templates and custom templates).
You can upload up to 100 records at a time.
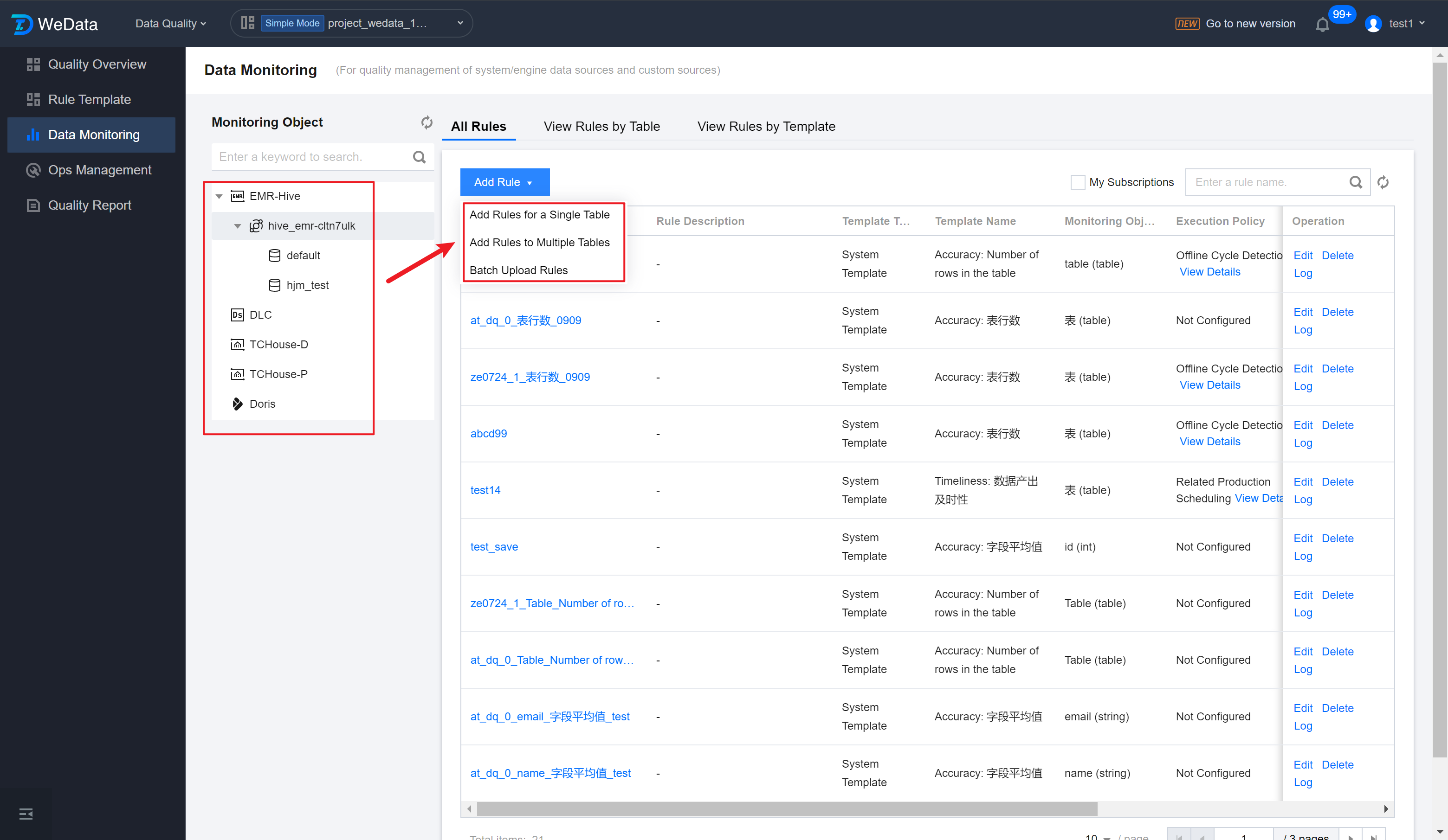
Create Monitoring Rule
Add Rule for Single Table
Support setting monitoring rules for a single table.
Use cases: Add multiple monitoring rules for a single database table at once.
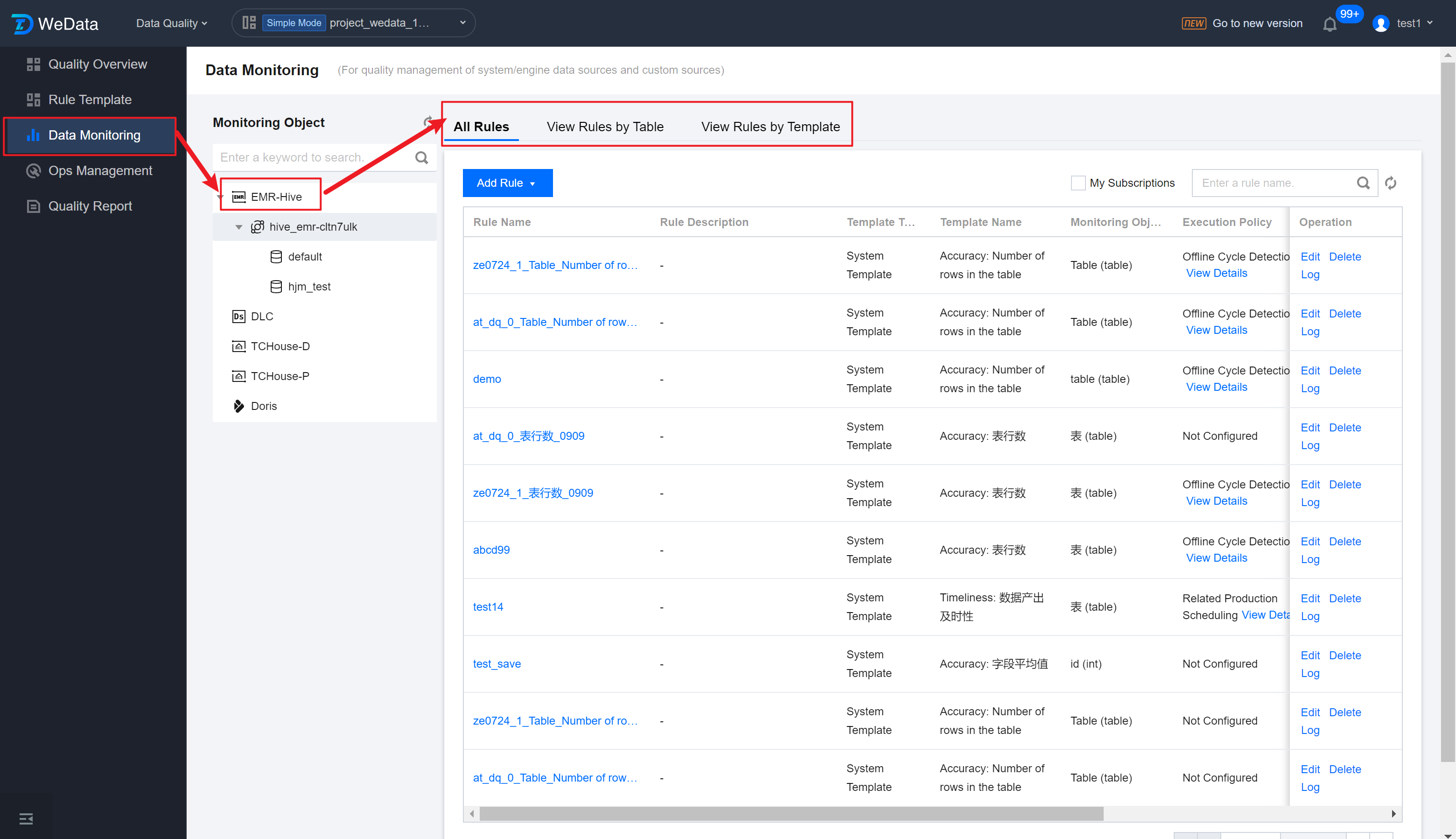
Step 1: Enter Data Monitoring Page
Enter the Data Quality > Data Monitoring > EMR interface, click Add Rules for a Single Table, to start adding a new quality rule.
Note:
Currently, WeData supports the following data source types: EMR-Hive, DLC, TCHouse-P, TCHouse-D, and Doris.
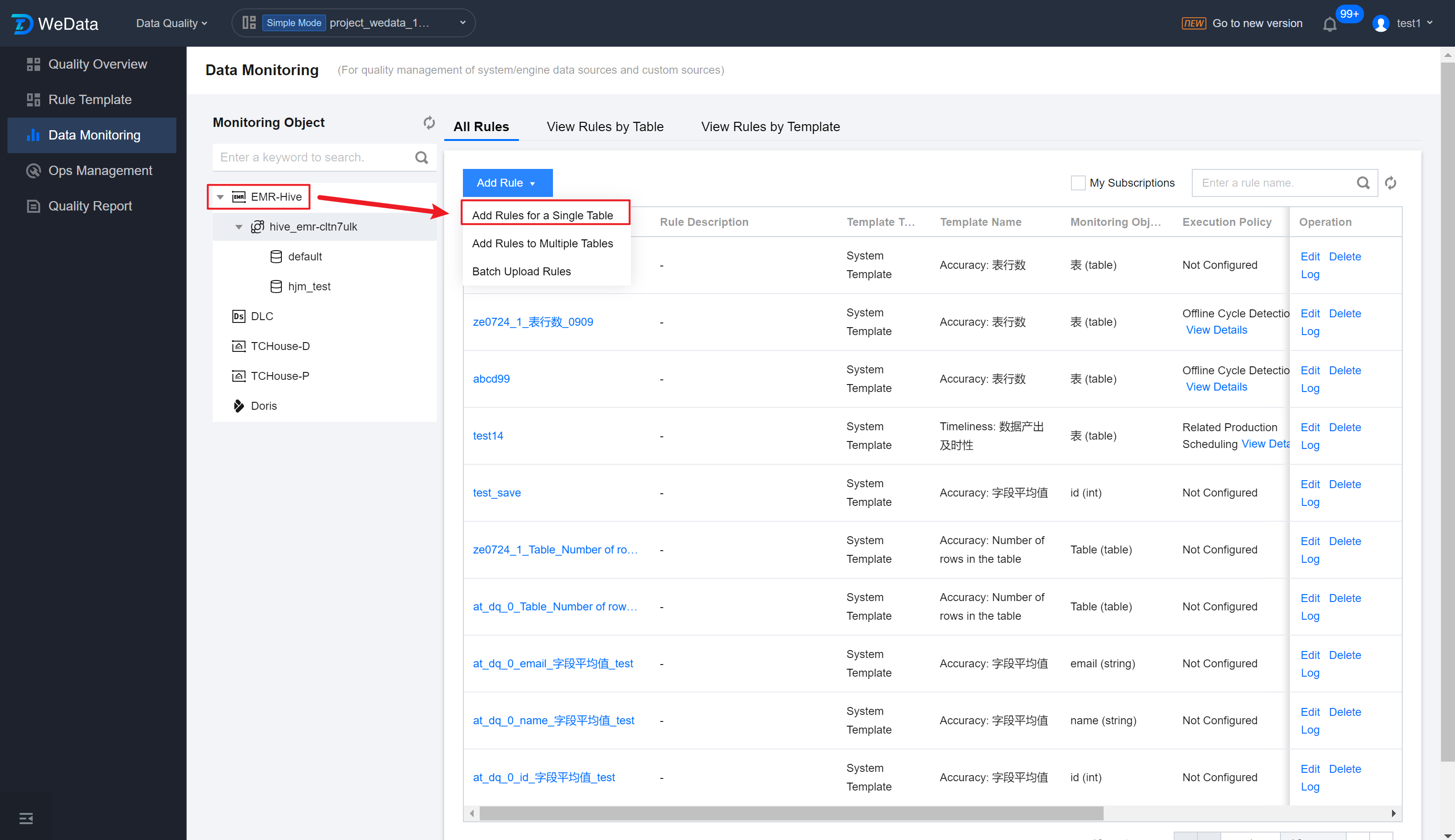
Step 2: Select Monitoring Object
Enter the Add Rules for a Single Table interface, select the data source, database, and monitoring table in sequence, click Add Monitoring Rule.
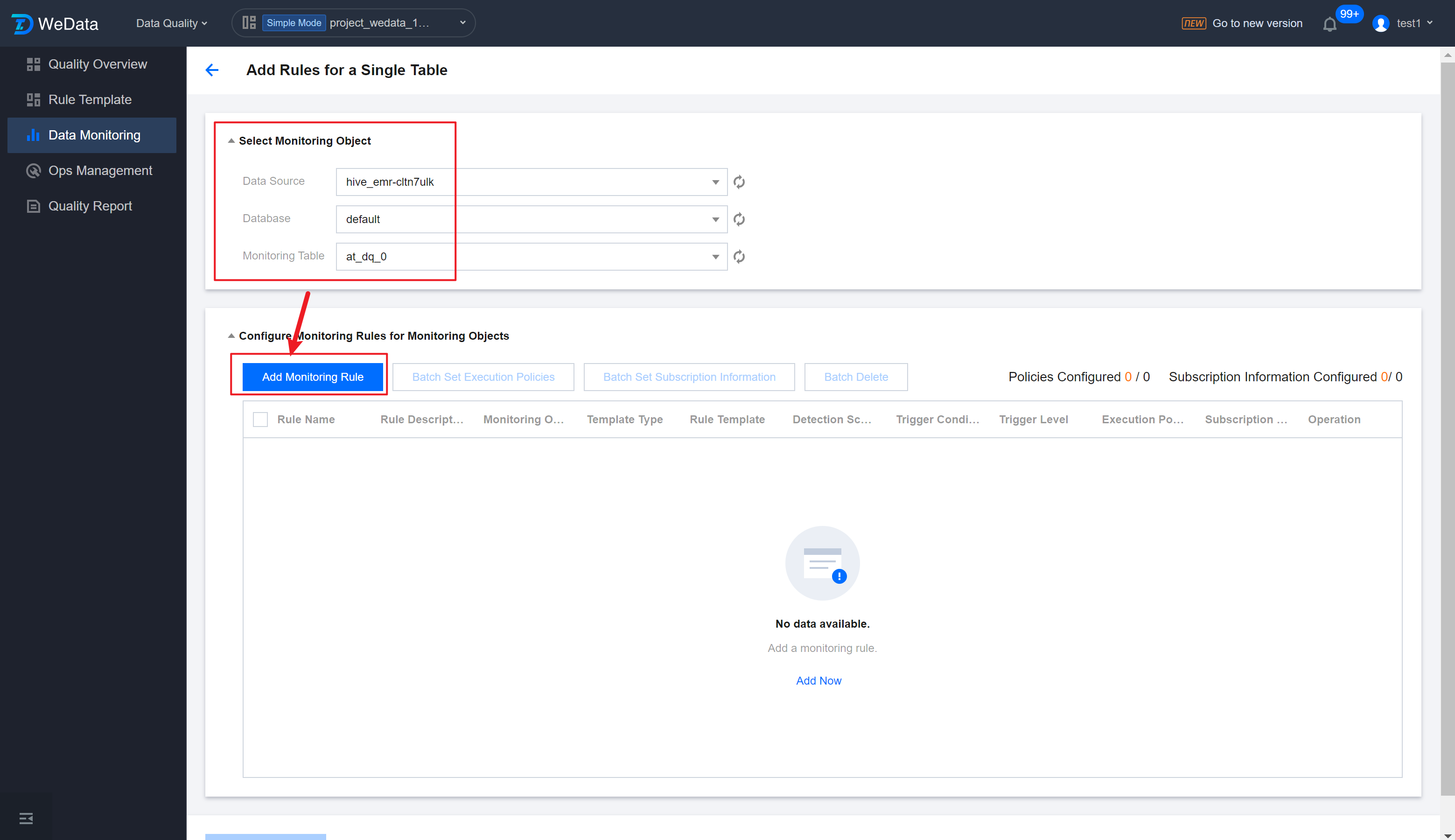
Step 3: Add Monitoring Rule
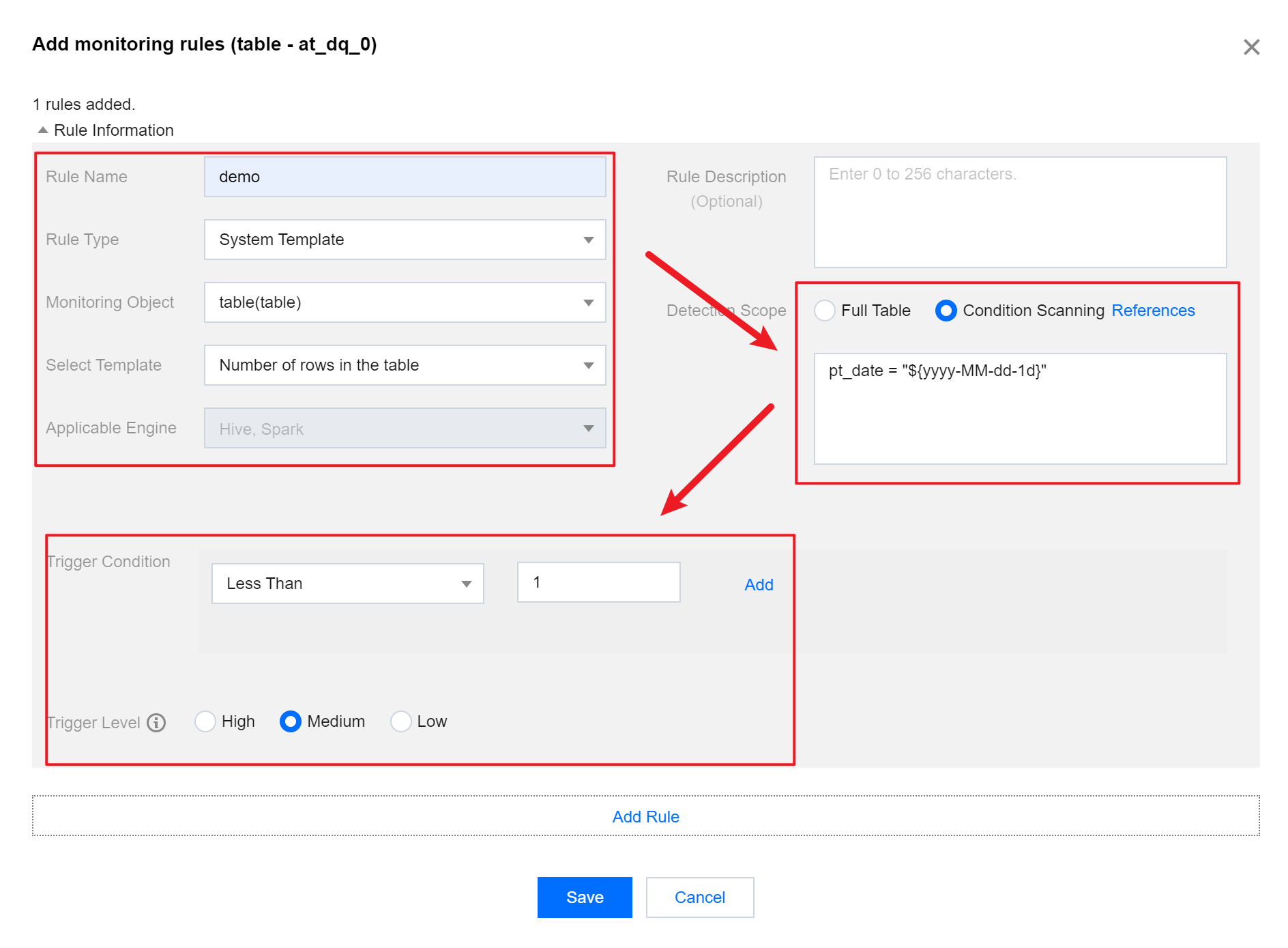
In the pop-up to add a new Monitoring Rule, fill in the following information, click Save.
Explanation:
Element
Note
Rule Category
Here, you can choose a System Template, a Custom Template, or Custom SQL:
System Template: WeData has 56 built-in rule templates that can be tried for free. Detailed descriptions of each template can be found in System Template Description.
Custom Template: You can add rules applicable to your business in the rule template menu for easy reuse. Detailed operation instructions can be found in Custom Template Description.
Select Template: Choose an already added custom template.
Database Table Parameters: The page will render based on the SQL statements filled in the custom template, allowing users to choose.
table_1 represents the currently selected table; table_2...table_n represent other tables that need to be specified (currently only one is supported).
${table_1.column_1}...${table_1.column_n} represent the fields within the table, and the specific fields need to be selected.
where Parameter: The page will render based on the SQL statements filled in the custom template, allowing users to choose.
${param_1}...${param_n} represent the parameters in the where condition, and the specific values need to be filled in.
Custom SQL: You can directly fill in the SQL statement as a detection rule.
Monitored object: Only tables are supported.
Custom Dimension: Need to select from six dimensions.
Applicable engine: Different engines can be selected based on different data sources, for example, Hive tables support Hive and Spark.
SQL Statements: An SQL statement needs to be filled in here with the following requirements:
The result must be one row and one column, i.e., a fixed value.
Only partition variables are allowed, such as ${yyyy-MM-dd}.
Do not allow the use of table name and column name variables.
Monitoring Object
For example, in the system template, the monitored object can be classified as Table-level and Field-level:
Table-level, can monitor the number of table rows, table size (only supports Hive tables).
Field-Level, can monitor whether a field is empty, duplicated, its average value, maximum value, minimum value, etc.
Select Template
This will be filtered based on rule type and monitored objects.
For example, select System template, choose Table-level as the monitored object, and you can only select Number of table rows, Table size, etc.
Detection Range
You can choose between conditional scan and whole table.
It is recommended to choose Conditional Scan.
Partition where conditions can be filled in, for example:
op_date='${yyyy-MM-dd-1d}'
Note:
Typically, partition fields are specified here to avoid full table scans for every quality task, thus preventing a waste of computing resources.
In SQL, ${yyyy-MM-dd-1d} is a date variable representing the day before the execution date. It will be replaced with the specific date when the quality task is executed.
For example: When the quality task is executed at 2024-05-02 00:00:00, ${yyyy-MM-dd-1d} will be replaced with 2024-05-01.
Comparators can select range values and size values.
Example: Number of table rows less than 1. Combined with the time variable filled in the detection range, it means: When there is no new data yesterday, trigger the alarm.
The trigger condition filled here is abnormal value, which means conditions for triggering alerts.
Trigger Level
Select Medium.
Trigger levels can be categorized into: High, Medium, Low.
High: When an alert is triggered, immediately block downstream task execution (only effective when linked with a production task).
Medium: Only trigger an alert.
Low: Does not trigger an alarm, only displays the result as abnormal.
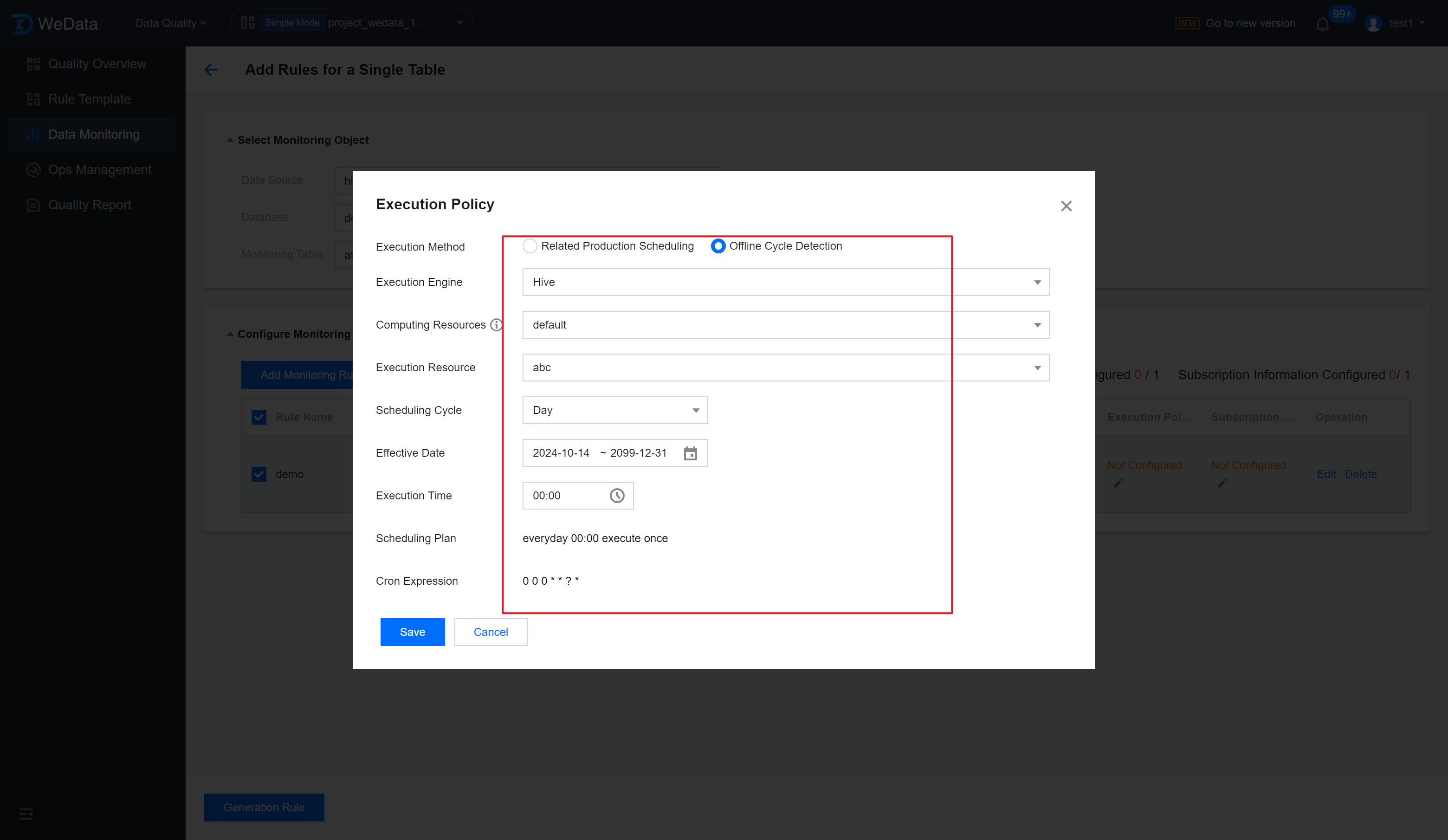
Step 4: Set Execution Strategy
After clicking Batch Set Execution Policies , enter the Execution Policies setting page. After setting up the batch execution policies, click Save.
Explanation:
Element
Note
Execution Method
You can select Related Production Scheduling and Offline Cycle Detection.
Associate Production Scheduling: That is, associated scheduling. Quality tasks are linked with production tasks (data synchronization tasks or data development tasks), and running quality rule tasks are inserted after the completion of production tasks. If an anomaly is found, the handler will be notified immediately to address the issue, and depending on the task level, downstream tasks may be blocked to prevent the problem data from expanding.
Select task: You can associate data synchronization tasks and data development tasks.
Note:
The same quality inspection task can be associated with multiple production tasks; likewise, the same production task can be associated with multiple quality inspection tasks.
Offline Periodic Detection: That is, independent scheduling. For selected database tables, the core business fields are set for periodic quality inspections at a self-defined frequency such as daily, hourly, or by minute. Quality tasks will be executed at the set period, and if anomalies are detected, subscribers will be notified immediately.
Scheduling Period: Monthly, weekly, daily, hourly, or by minute.
Effective Date: Select the effective time range.
Interval: When selecting daily or hourly, you can choose the task interval time.
Specify Date: When selecting by month or by week, you need to set the specific date, such as the day of the week or the date of the month.
Execution Time: When selecting monthly, weekly, or daily, you need to set the specific runtime.
Execution Engine
Different data sources can select different engines.
EMR-Hive: You can choose Hive or Spark. Generally, Hive tables can directly select the Hive engine.
DLC: You need to select the DLC data engine from the dropdown (includes Standard Engine and SuperSQL Engine).
TCHouse-P: Only TCHouse-P can be selected.
TCHouse-D: Only TCHouse-D can be selected.
Doris: Only Doris can be selected.
Computing Resources
Different data sources can select different computing resources.
When the compute engine is EMR: You can select a resource group from the EMR cluster here; usually, you can directly select the default.
When the compute engine is DLC: You can select a resource service from the DLC here.
TCHouse-P: No selection needed
TCHouse-D: No selection needed.
Doris: No selection needed.
Execute Resources
The execute resources here refer to the schedule resource group that the project has already bound.
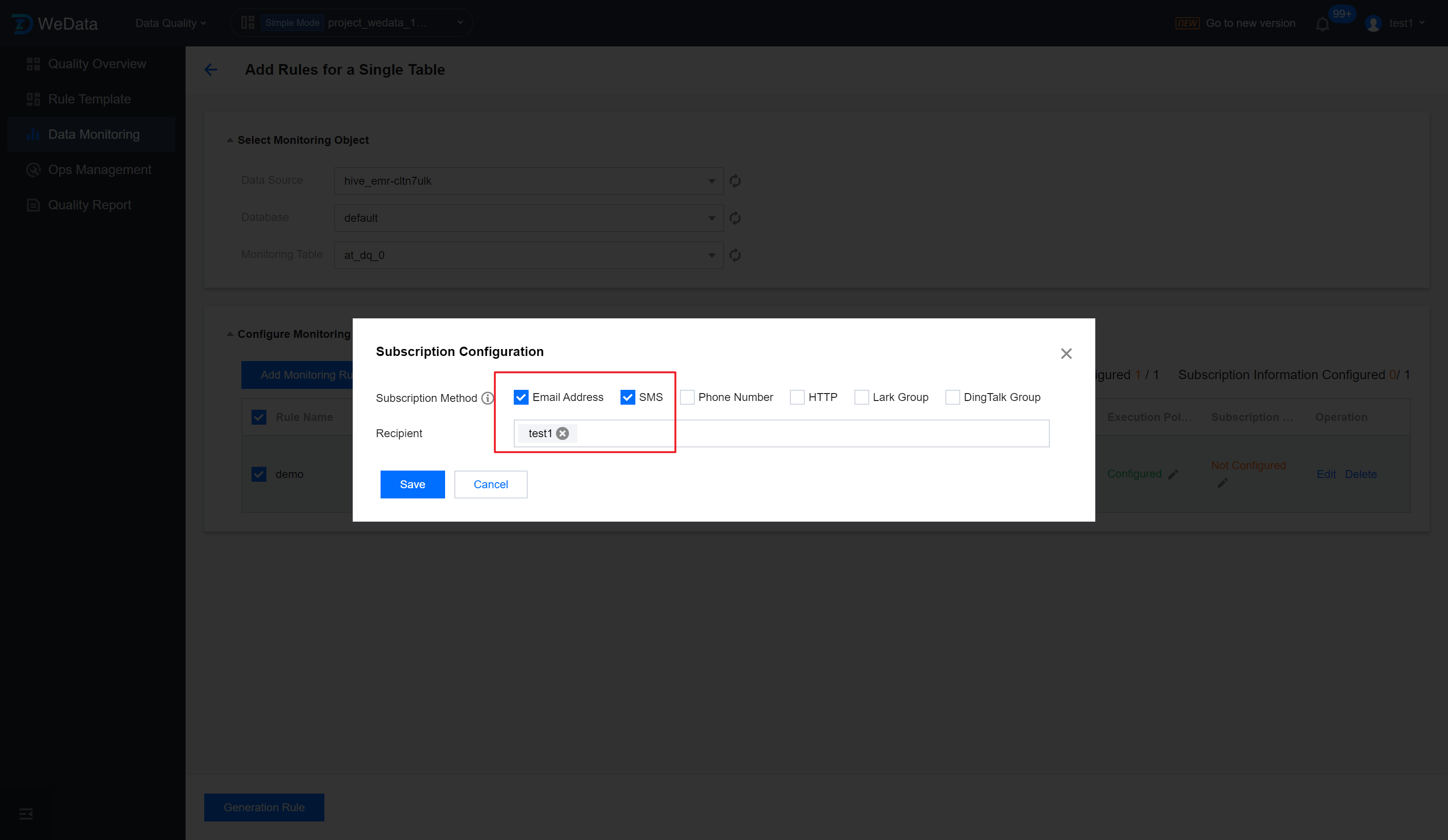
Step 5: Set up subscription
When the running result of the quality inspection task meets the trigger condition (i.e., the result is unexpected, the detection result fails), how and to whom a notification should be sent.
Enter the Subscription Configuration interface, check the Subscription Method, set up the Recipient, and click Save.
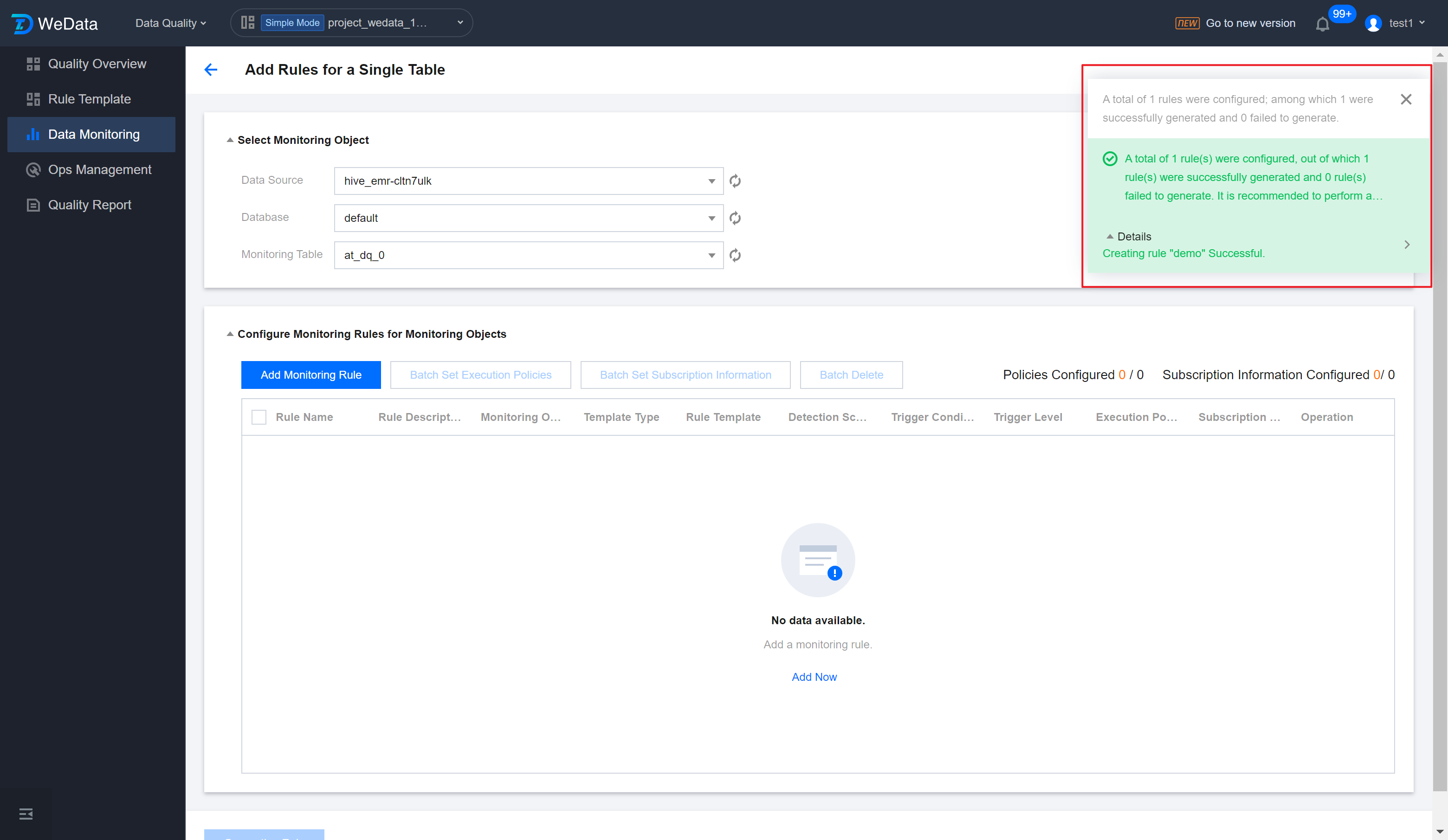
Step 6: Generate rules and view details
1. Enter the Add Rule for Single Table interface, click Generate Rules, you must click Generate Rules to generate quality inspection rules.
2. You can click Details in the upper right corner of the interface to enter the Rule List.
Step 7: Trial run
1. Enter the rule list at the table dimension, click Trial Run.
2. Modify the scheduling time, and click Start trial run; after the trial run ends, you can click Click to view running results.
Note:
The scheduling time filled in here will modify the partition time variables.
For example, if you fill in 2024-05-02 here, ${yyyy-MM-dd} will represent 2024-05-02, and ${yyyy-MM-dd-1d} will represent 2024-05-01.
Step 8: View trial run results
1. After entering the Execution instance and result page, you can click the left Dropdown triangle to expand the Rule details.
2. Click the Execution history of a rule to view the Historical running results.
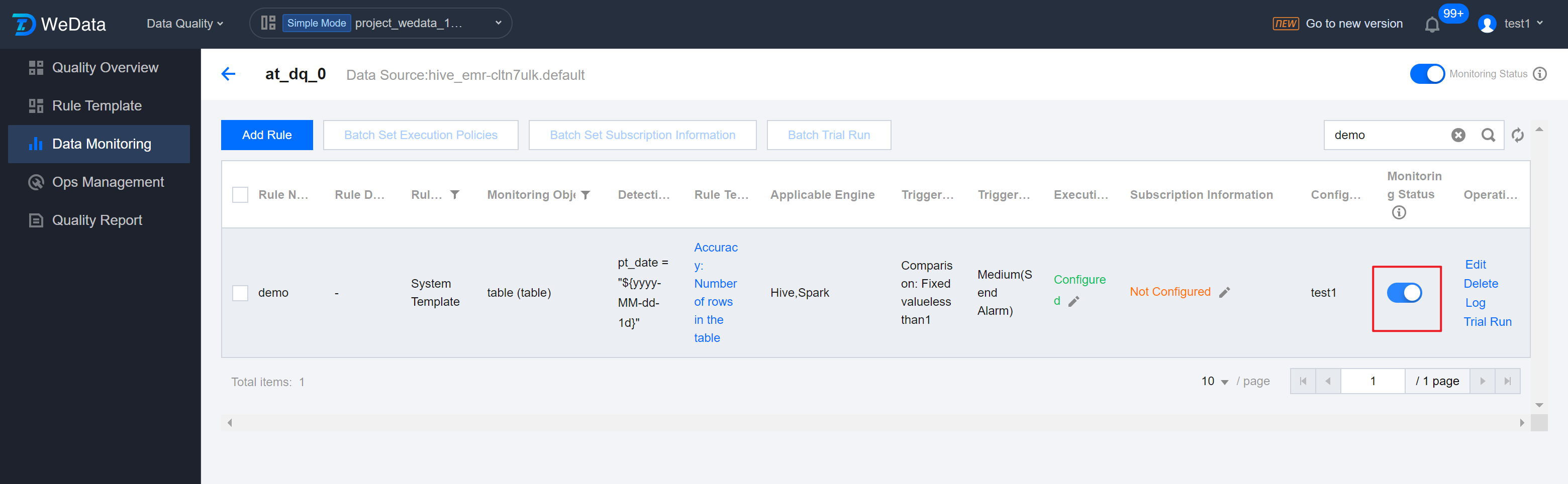
Step 9: Enable Monitoring
If there are no issues with the trial run results, you can return to the quality rule list at the table dimension and turn Monitoring Status to ON.
Note:
Only monitoring rules in the Enabled state will run automatically.
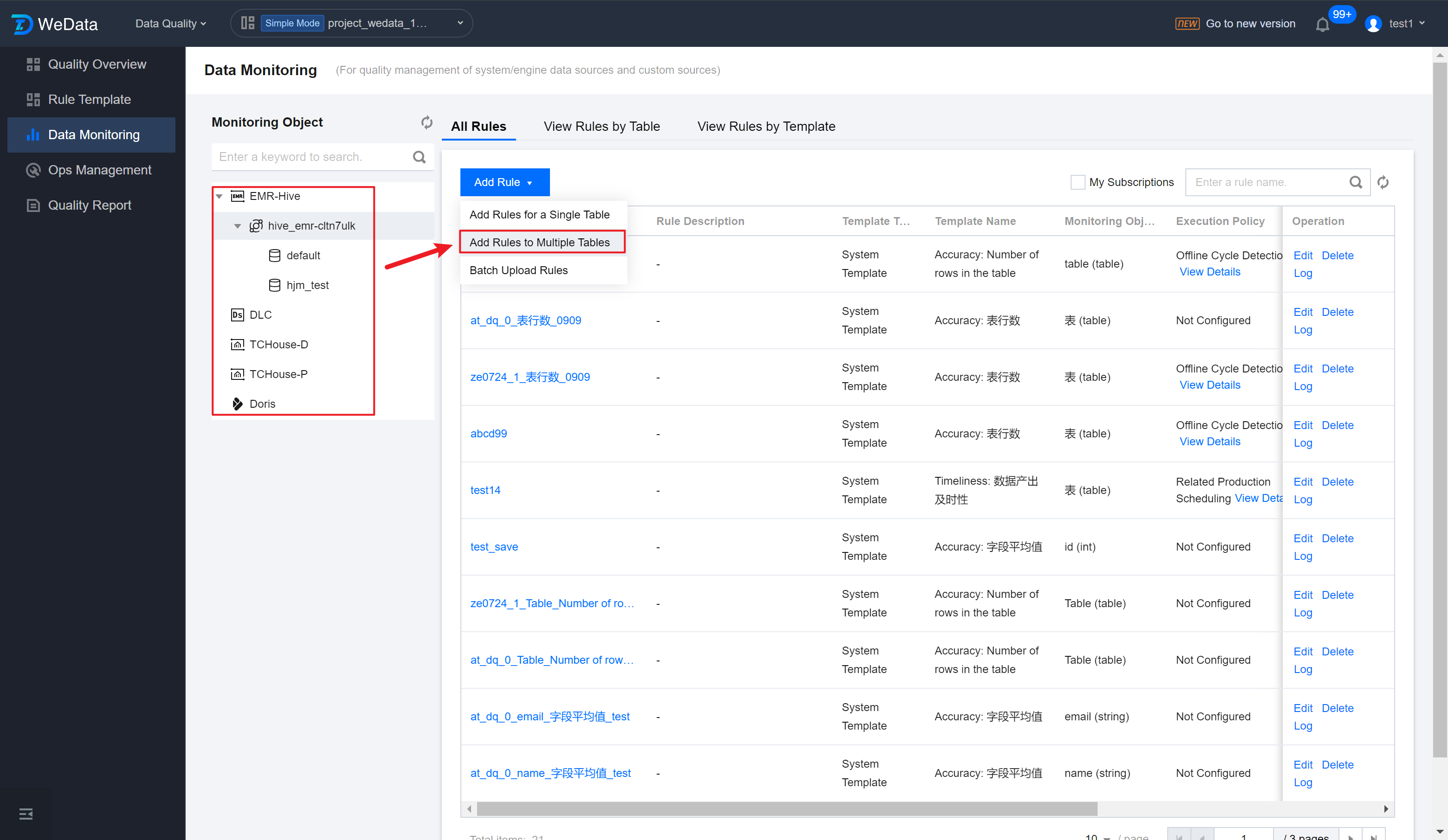
Add Rules to Multiple Tables
Support setting monitoring rules for multiple tables.
Use cases: Add the same monitoring rule to multiple databases and tables at once.
Step 1: Enter Data Monitoring Page
Enter the Data Quality > Data Monitoring > EMR interface, click Add Rules to Multiple Tables to start adding multiple monitoring rules.
Note:
Currently, WeData supports the following data source types: EMR-Hive, DLC, TCHouse-P, TCHouse-D, and Doris.
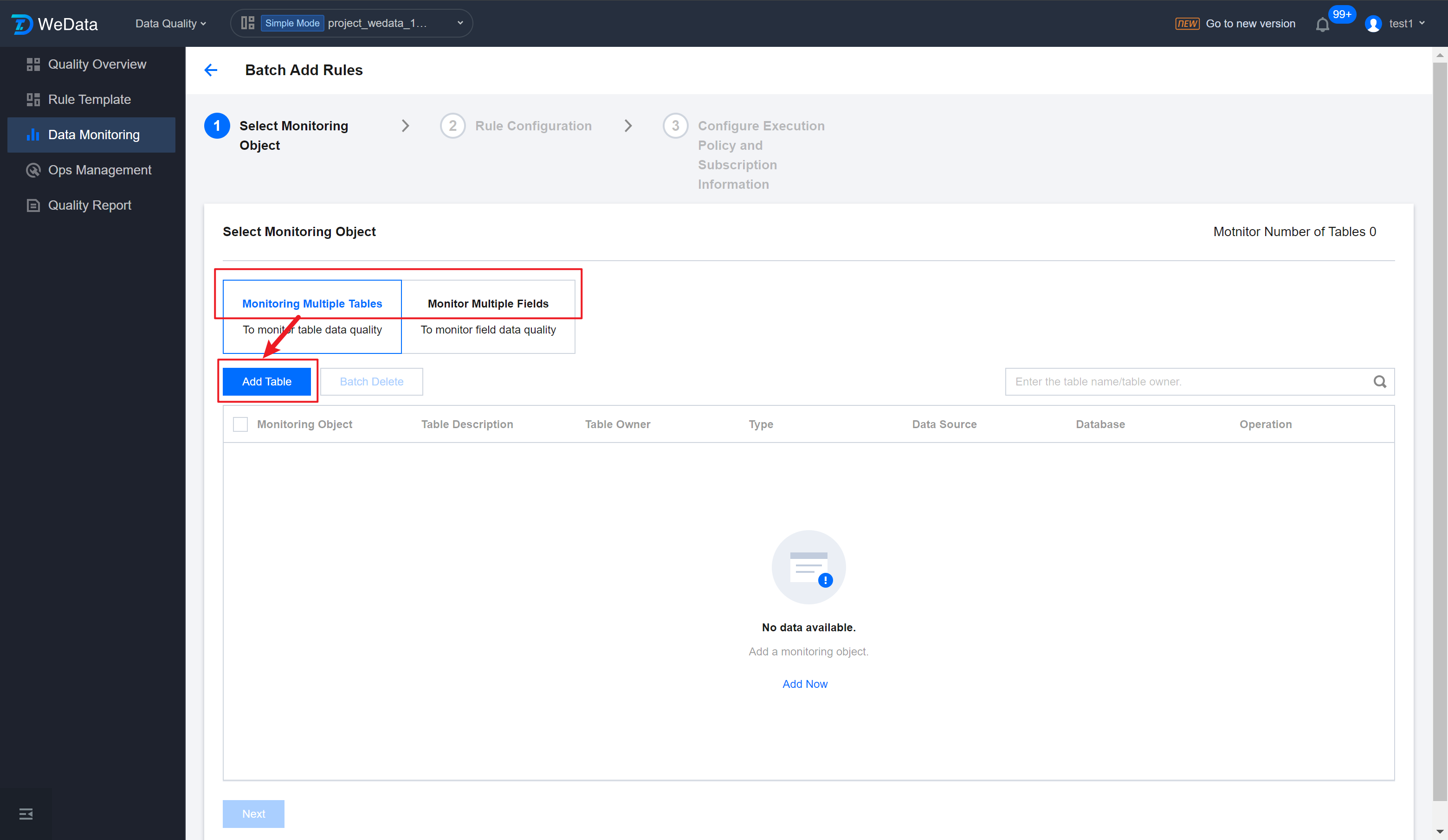
Step 2: Set Monitoring Scope
1. Click Batch Add Rules to enter the Batch Add Rules interface. You can choose to Monitor Multiple Tables or Monitor Multiple Fields.
Multi-table: Add multiple tables from the same data source, can cross database.
Multiple fields: Add multiple tables from the same data source, can cross databases and tables.
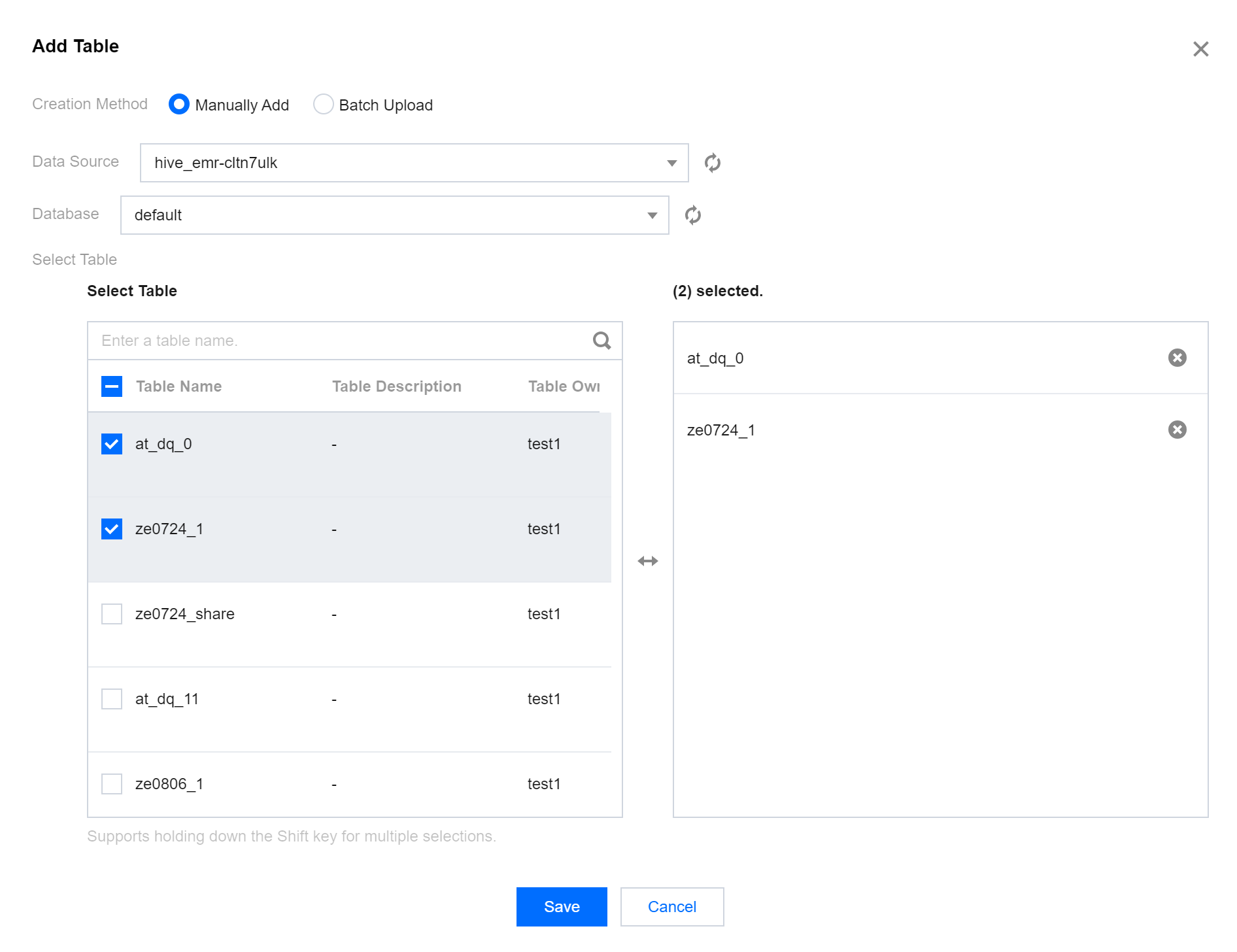
2. click Add Table, Add table/field:
Manual Addition: Just check it.
Bulk Upload: Requires uploading an Excel file, monitor multiple tables and multiple fields templates are different.
Monitor Multiple Tables: The Excel file contains three columns: Data Source Name, Database Name, Table Name.
Monitor Multiple Fields: The Excel file contains four columns: Data Source Name, Database Name, Table Name, Column Name.
3. click Next to enter the rule configuration page.
Step 3: Configure Monitoring Rules
1. Select Rule Template: Only supports System Templates and Custom Templates
System Templates: WeData has 56 built-in rule templates that can be tried for free. Detailed descriptions of each template can be found in System Template Description.
Custom Templates: You can add rules applicable to your business in the rule template menu for easy reuse. Detailed operation instructions can be found in Custom Template Description.
Database Table Parameters: The page will render based on the SQL statements filled in the custom template, allowing users to choose.
table_1 represents the currently selected table; table_2...table_n represent other tables that need to be specified (currently only one is supported).
${table_1.column_1}...${table_1.column_n} represent the fields within the table, and the specific fields need to be selected.
where Parameter: The page will render based on the SQL statements filled in the custom template, allowing users to choose.
${param_1}...${param_n} represent the parameters in the where condition, and the specific values need to be filled in.
2. Select Template: This will be filtered based on rule type and monitored objects.
For example, select System template, choose Table-level as the monitored object, and you can only select Number of table rows, Table size, etc.
3. Trigger Conditions: Comparators can select range values and size values.
Example: Number of table rows less than 1. Combined with the time variable filled in the detection range, it means: When there is no new data yesterday, trigger the alarm.
The trigger condition entered here is Abnormal Value, meaning: the condition that triggers the alert.
4. click Next to enter the execution policy configuration page.
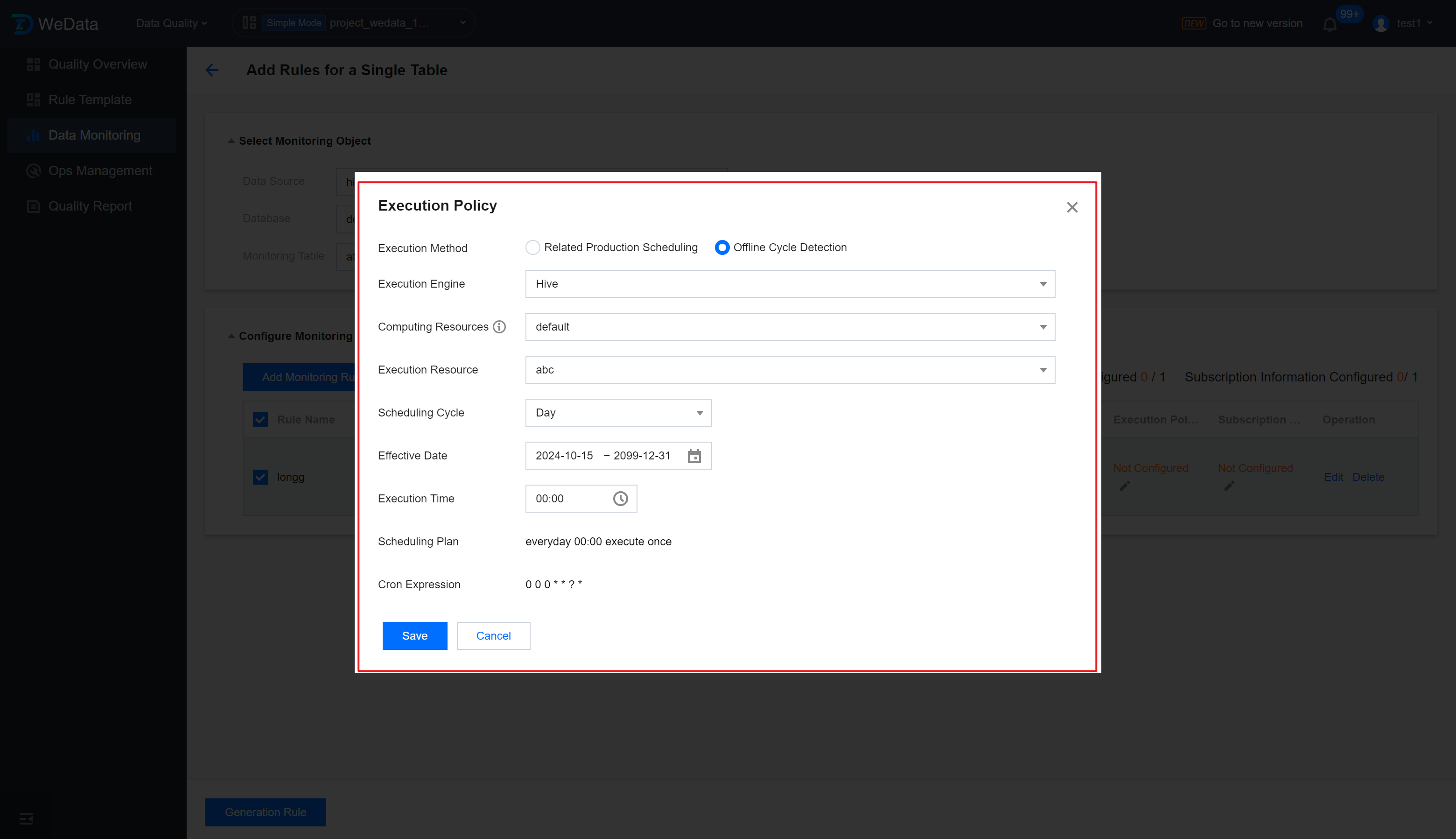
Step 4: Set Execution Strategy
After clicking Batch Set Execution Policies , enter the Execution Policies setting page. After setting up the batch execution policies, click Save.
Explanation:
Element
Note
Execution Method
You can select Related Production Scheduling and Offline Cycle Detection.
Associate Production Scheduling: That is, associated scheduling. Quality tasks are linked with production tasks (data synchronization tasks or data development tasks), and running quality rule tasks are inserted after the completion of production tasks. If an anomaly is found, the handler will be notified immediately to address the issue, and depending on the task level, downstream tasks may be blocked to prevent the problem data from expanding.
Select task: You can associate data synchronization tasks and data development tasks.
Note:
The same quality inspection task can be associated with multiple production tasks; likewise, the same production task can be associated with multiple quality inspection tasks.
Offline Periodic Detection: That is, independent scheduling. For selected database tables, the core business fields are set for periodic quality inspections at a self-defined frequency such as daily, hourly, or by minute. Quality tasks will be executed at the set period, and if anomalies are detected, subscribers will be notified immediately.
Scheduling Period: Monthly, weekly, daily, hourly, or by minute.
Effective Date: Select the effective time range.
Interval: When selecting daily or hourly, you can choose the task interval time.
Specify Date: When selecting by month or by week, you need to set the specific date, such as the day of the week or the date of the month.
Execution Time: When selecting monthly, weekly, or daily, you need to set the specific runtime.
Execution Engine
Different data sources can select different engines.
EMR-Hive: You can choose Hive or Spark. Generally, Hive tables can directly select the Hive engine.
DLC: You need to select the DLC data engine from the dropdown (includes Standard Engine and SuperSQL Engine).
TCHouse-P: Only TCHouse-P can be selected.
TCHouse-D: Only TCHouse-D can be selected.
Doris: Only Doris can be selected.
Computing Resources
Different data sources can select different computing resources.
When the compute engine is EMR: You can select a resource group from the EMR cluster here; usually, you can directly select the default.
When the compute engine is DLC: You can select a resource service from the DLC here.
TCHouse-P: No selection needed.
TCHouse-D: No selection needed.
Doris: No selection needed.
Execute Resources
The execute resources here refer to the schedule resource group that the project has already bound.
Step 5: Set up subscription
Set subscription notifications. When the quality inspection task's result meets the trigger conditions (i.e., the result is unexpected, and the detection fails), specify how and to whom the notification should be sent.
1. Enter the Batch Settings for Subscription Information interface to set subscription information in bulk.
2. In the popup subscription settings page, check your required Subscription Method, set the Recipient. Click Save.
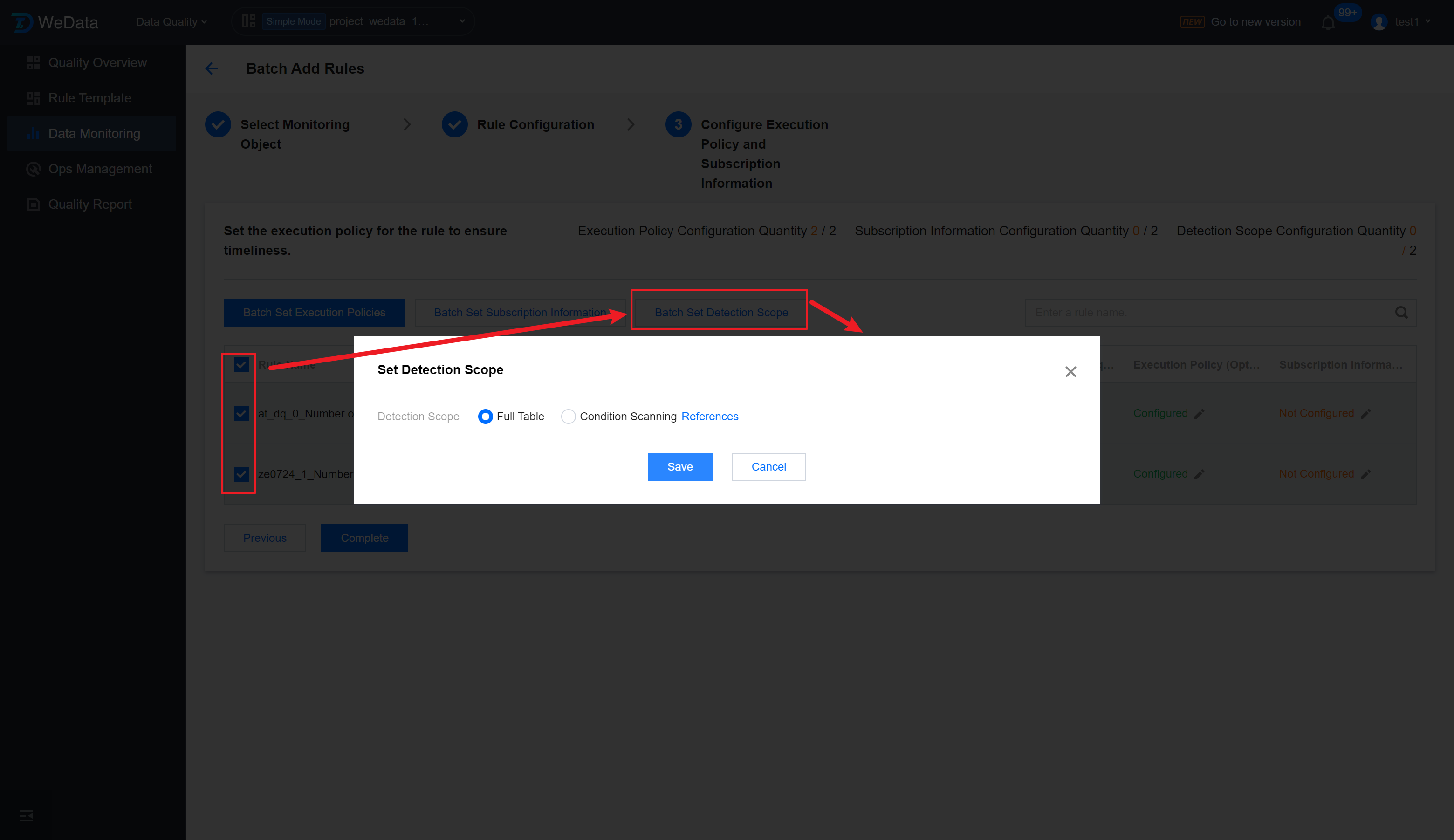
Step 6: Set Detection Scope
1. Click Batch Set Detection Scope to enter the Set Detection Scope interface, and you can set the detection scope in bulk.
2. Add the following information in the popup page:
You can choose between Conditional Scan and Whole Table. It is recommended to choose Conditional Scan.
Partition where conditions can be filled in, for example:
pt_date='${yyyy-MM-dd-1d}'
Note:
Typically, partition fields are specified here to avoid full table scans for every quality task, thus preventing a waste of computing resources.
In SQL, ${yyyy-MM-dd-1d} is a date variable representing the day before the execution date. It will be replaced with the specific date when the quality task is executed.
For example: When the quality task executes on 2024-05-02 00:00:00, ${yyyy-MM-dd-1d} will be replaced with 2024-05-01.
1. Enter the rule list at the table dimension, click Trial Run.
2. Modify the scheduling time, and click Start trial run; after the trial run ends, you can click Click to view running results.
Note:
The scheduling time filled in here will modify the partition time variables.
For example, if you fill in 2024-05-02 here, ${yyyy-MM-dd} will represent 2024-05-02, and ${yyyy-MM-dd-1d} will represent 2024-05-01.
Step 9: View and Enable Regulations
1. Enter the Data Quality > Data Monitoring > EMR > All Rules interface, find the regulation you need, and click Regulation Name.
2. Enter the table dimension monitoring rules list, in the monitoring status bar, click the Enable Rule button switch to activate the rule.
Batch Upload Rules
Upload an attachment by uploading an Excel file to add quality monitoring rules. Supports setting monitoring rules for multiple tables.
Use cases: Add multiple monitoring rules to multiple databases and tables at once.
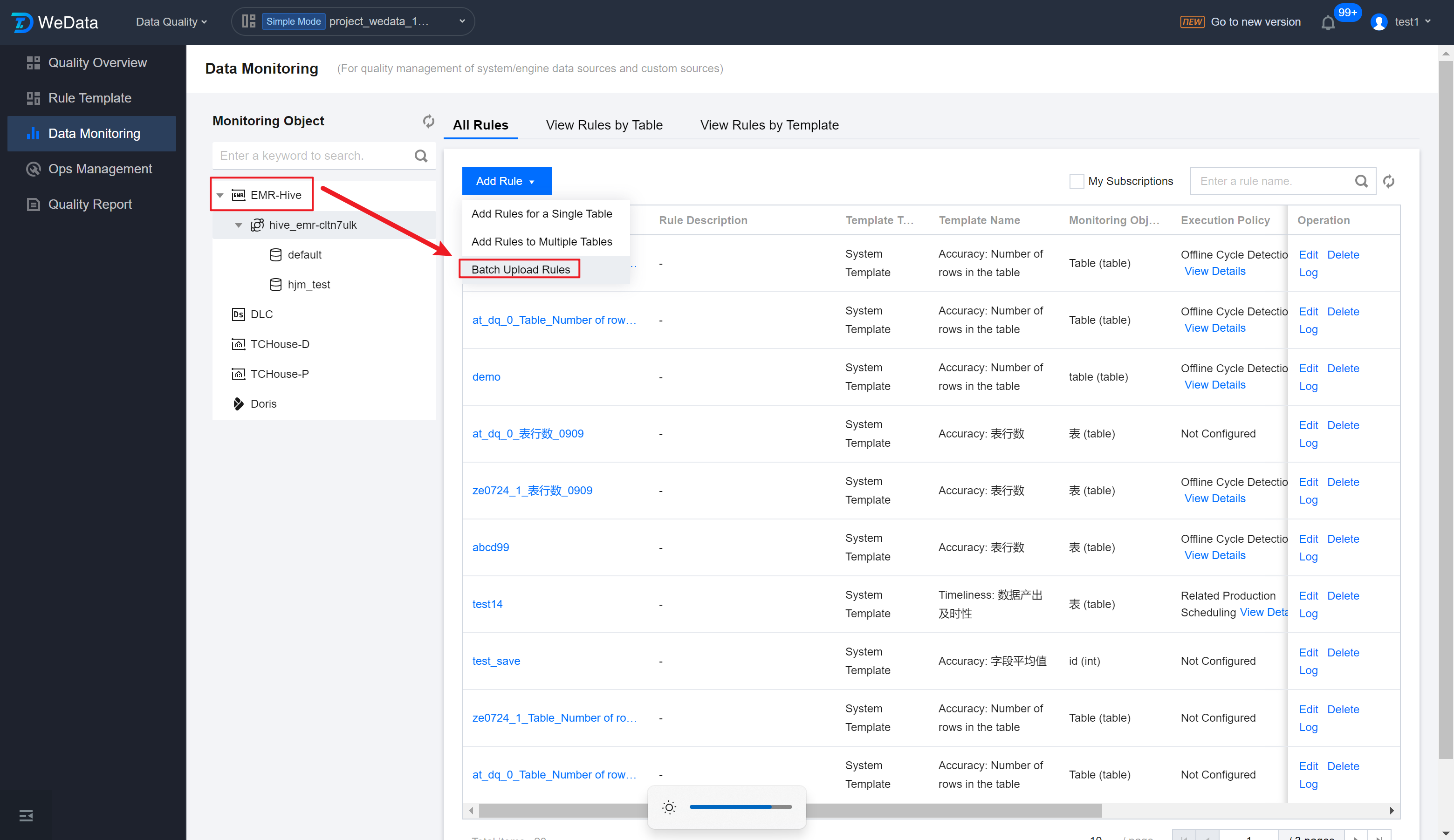
Step 1: Enter Data Monitoring Page
Enter the Data Quality > Data Monitoring > EMR interface, click Batch Upload Rules to add multiple quality rules.
Note:
Currently, WeData supports the following data source types: EMR-Hive, DLC, TCHouse-P, TCHouse-D, and Doris.
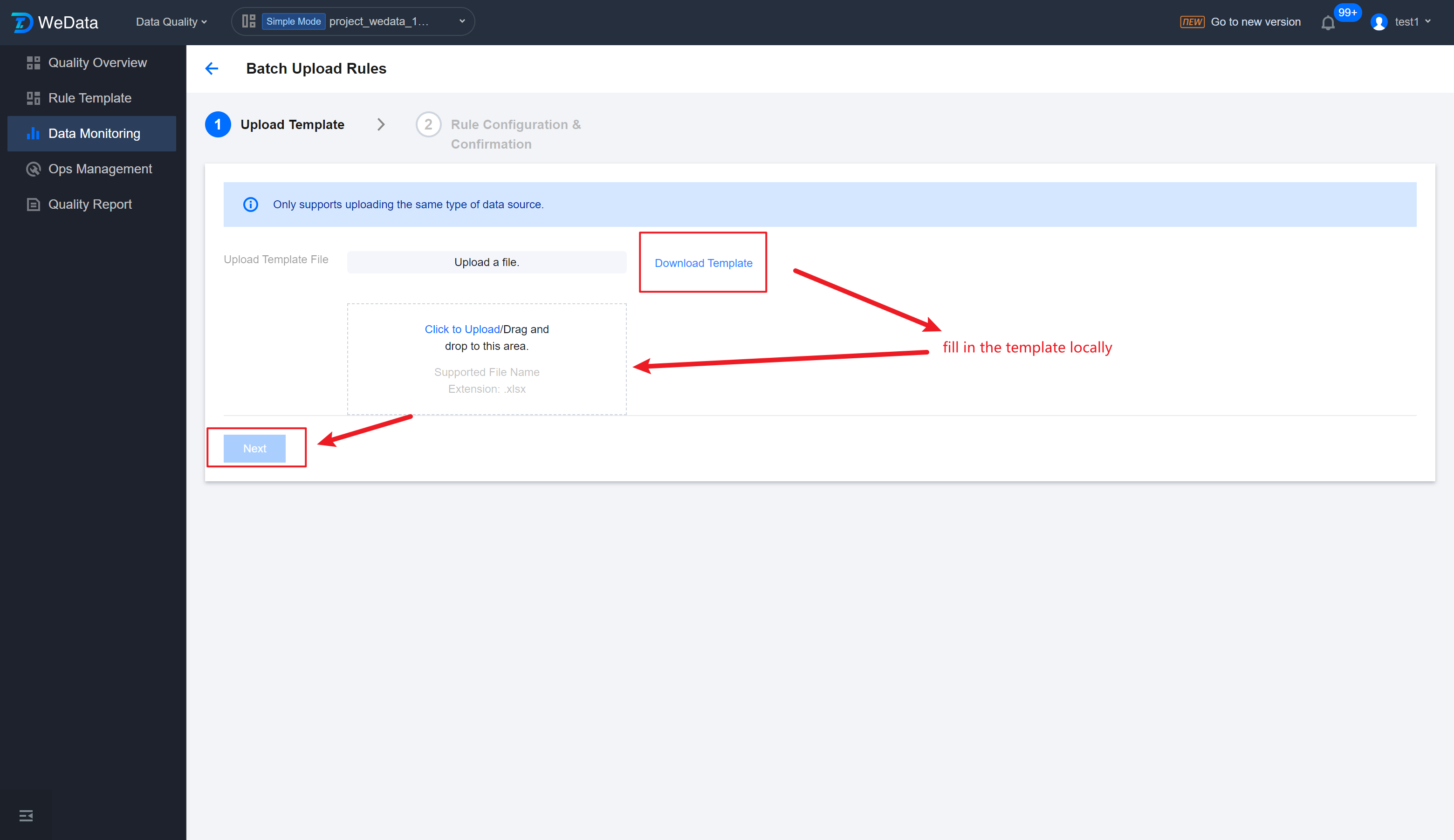
Step 2: Upload Template
1. Enter the Data Monitoring > Batch Upload Rules interface, in the upload template interface, click Download Template, modify it locally, then click Click to Upload to upload the template.
SQL Statements: An SQL statement needs to be filled in here with the following requirements:
The result must be one row and one column, i.e., a fixed value.
Only partition variables are allowed, such as ${yyyy-MM-dd}.
Do not allow the use of table name and column name variables.
Trigger Conditions: Comparators and comparison values should be separated by a colon.
Comparator: Enter in Chinese characters.
Comparison Value: Enter a numerical value.
2. Click Next to continue the configuration.
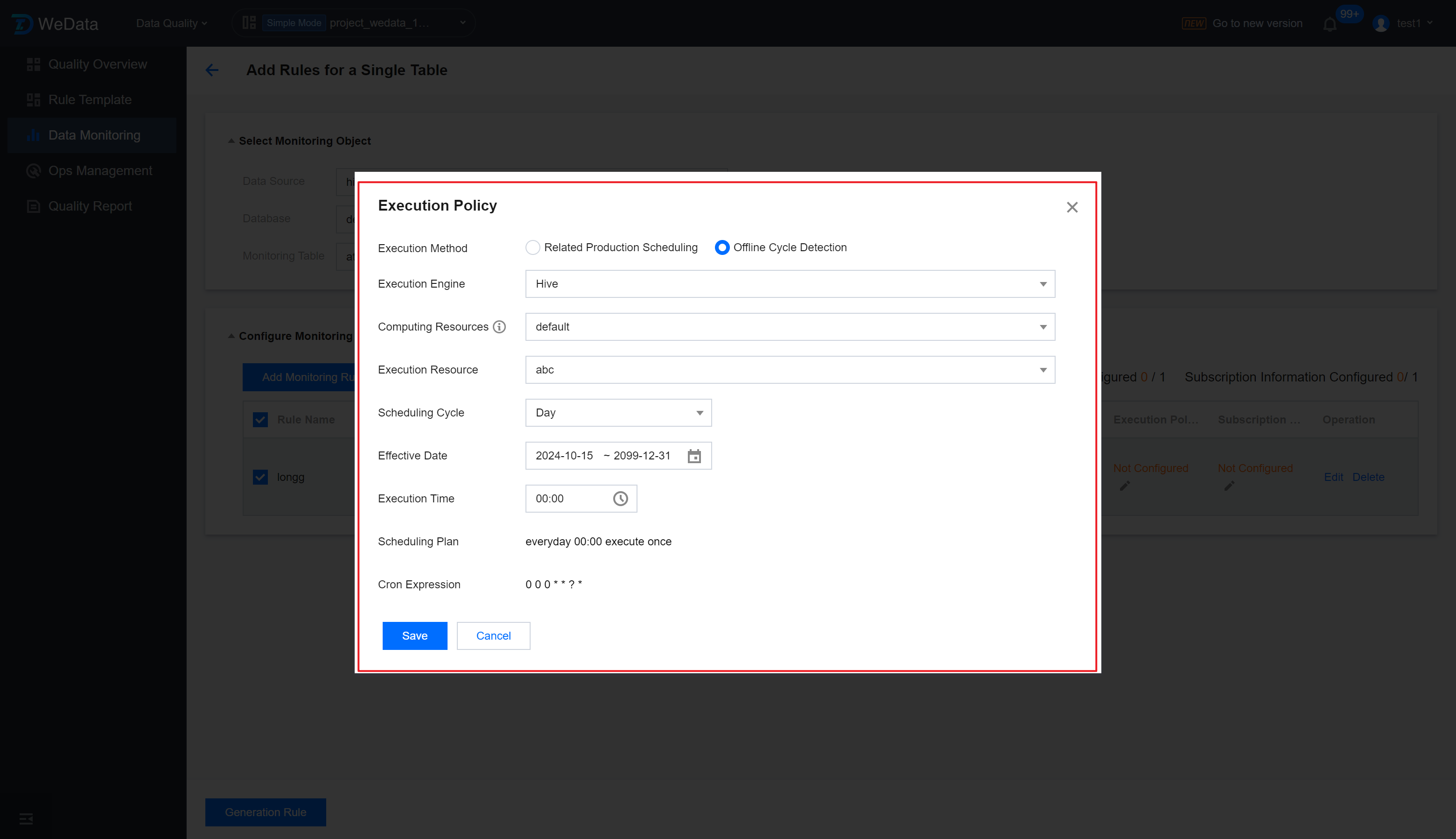
Step 3: Set Execution Strategy
After clicking Batch Set Execution Policies , enter the Execution Policies setting page. After setting up the batch execution policies, click Save.
Explanation:
Element
Note
Execution Method
You can select Related Production Scheduling and Offline Cycle Detection.
Associate Production Scheduling: That is, associated scheduling. Quality tasks are linked with production tasks (data synchronization tasks or data development tasks), and running quality rule tasks are inserted after the completion of production tasks. If an anomaly is found, the handler will be notified immediately to address the issue, and depending on the task level, downstream tasks may be blocked to prevent the problem data from expanding.
Select task: You can associate data synchronization tasks and data development tasks.
Note:
The same quality inspection task can be associated with multiple production tasks; likewise, the same production task can be associated with multiple quality inspection tasks.
Offline Periodic Detection: That is, independent scheduling. For selected database tables, the core business fields are set for periodic quality inspections at a self-defined frequency such as daily, hourly, or by minute. Quality tasks will be executed at the set period, and if anomalies are detected, subscribers will be notified immediately.
Scheduling Period: Monthly, weekly, daily, hourly, or by minute.
Effective Date: Select the effective time range.
Interval: When selecting daily or hourly, you can choose the task interval time.
Specify Date: When selecting by month or by week, you need to set the specific date, such as the day of the week or the date of the month.
Execution Time: When selecting monthly, weekly, or daily, you need to set the specific runtime.
Execution Engine
Different data sources can select different engines.
EMR-Hive: You can choose Hive or Spark. Generally, Hive tables can directly select the Hive engine.
DLC: A dropdown selection of the DLC data engine is required ().
TCHouse-P: Only TCHouse-P can be selected.
TCHouse-D: Only TCHouse-D can be selected.
Doris: Only Doris can be selected.
Computing Resources
Different data sources can select different computing resources.
When the compute engine is EMR: You can select a resource group from the EMR cluster here; usually, you can directly select the default.
When the compute engine is DLC: You can select a resource service from the DLC here.
TCHouse-P: No selection needed.
TCHouse-D: No selection needed.
Doris: No selection needed.
Execute Resources
The execute resources here refer to the schedule resource group that the project has already bound.
Step 5: Set up subscription
Set subscription notifications. When the quality inspection task's result meets the trigger conditions (i.e., the result is unexpected, and the detection fails), specify how and to whom the notification should be sent.
1. Enter the Batch Settings for Subscription Information interface to set subscription information in bulk.
2. In the popup subscription settings page, check your required Subscription Method, set the Recipient. Click Save.
Step 6: Complete Configuration
Check configuration integrity, and click Finish.
Step 7: View and Enable Rules
1. Enter the Data Quality > Data Monitoring > EMR > All Rules interface, find the regulation you need, and click Regulation Name.
2. Enter the table dimension monitoring rules list, in the monitoring status bar, click the Enable Rule button switch to activate the rule.
Viewing Monitoring Rules
Rule List
WeData supports three ways to view monitoring rules. Users can choose according to actual scenarios.
All Rules
Displays all monitoring rules under a data source.
You can select data source, database.
You can filter the rules you subscribed to.
View Rules by Table
Aggregates data by table dimension, showing the number of rules for each table.
You can select data source, database.
You can select the rules you subscribed to.
View Rules by Template
Aggregate data by template dimension, showing the number of rules for each table.
You can choose a System Template or a Custom Template.
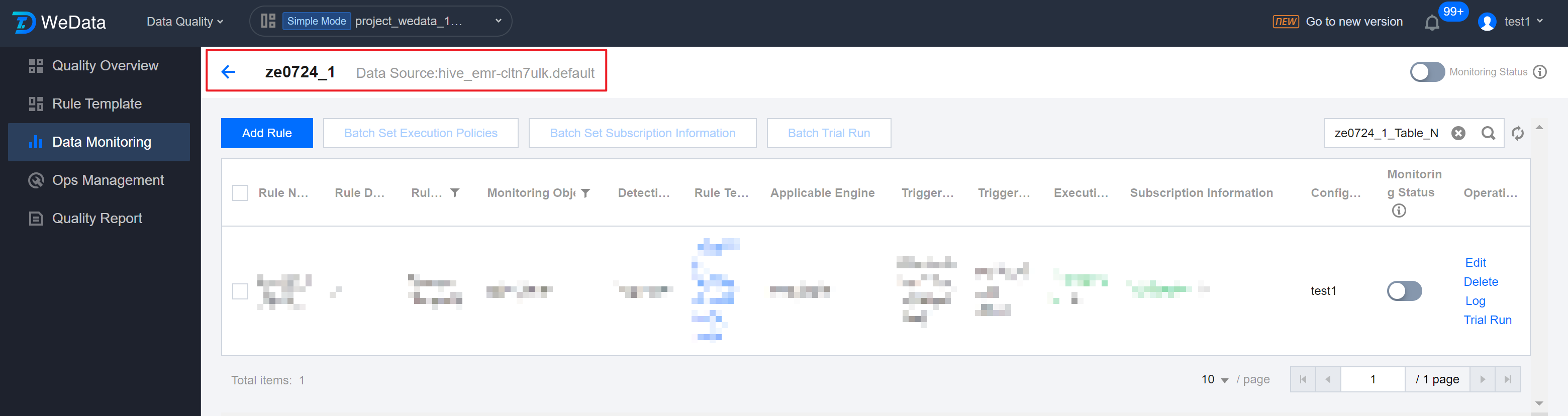
Rule List - Single Table View
1. Click on a rule to enter the rule list page at the table dimension.
2. On the Table Dimension Rule List Page, you can operate on a specific rule: Monitoring Status On/Off, Trial Run, View Log, etc.


 Yes
Yes
 No
No
Was this page helpful?