2. On the instance list page, select the name of the instance that requires configuring data collection rules and enter its details page.
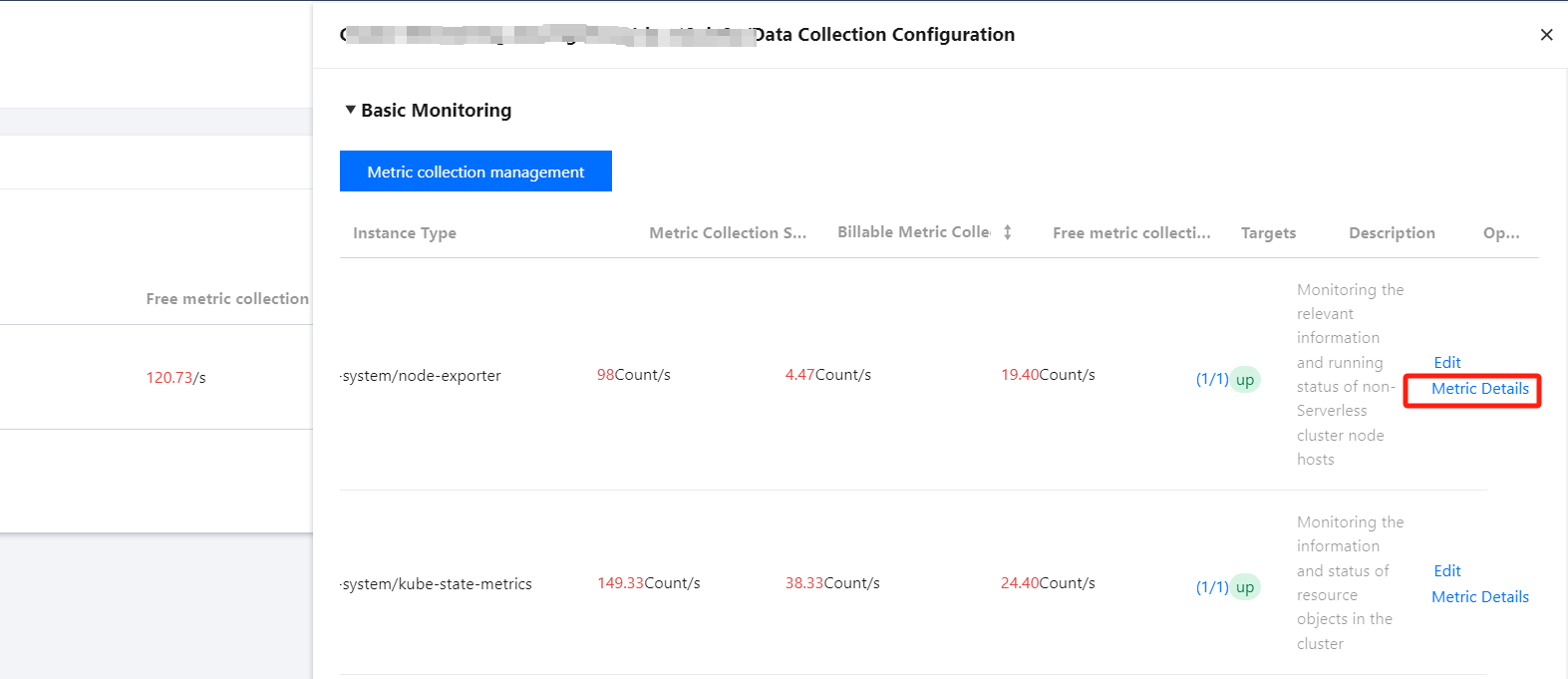
3. On the Data Collection page, click Integration with TKE, find the target cluster, and click Data Collection Configuration in the operation bar, as shown below:
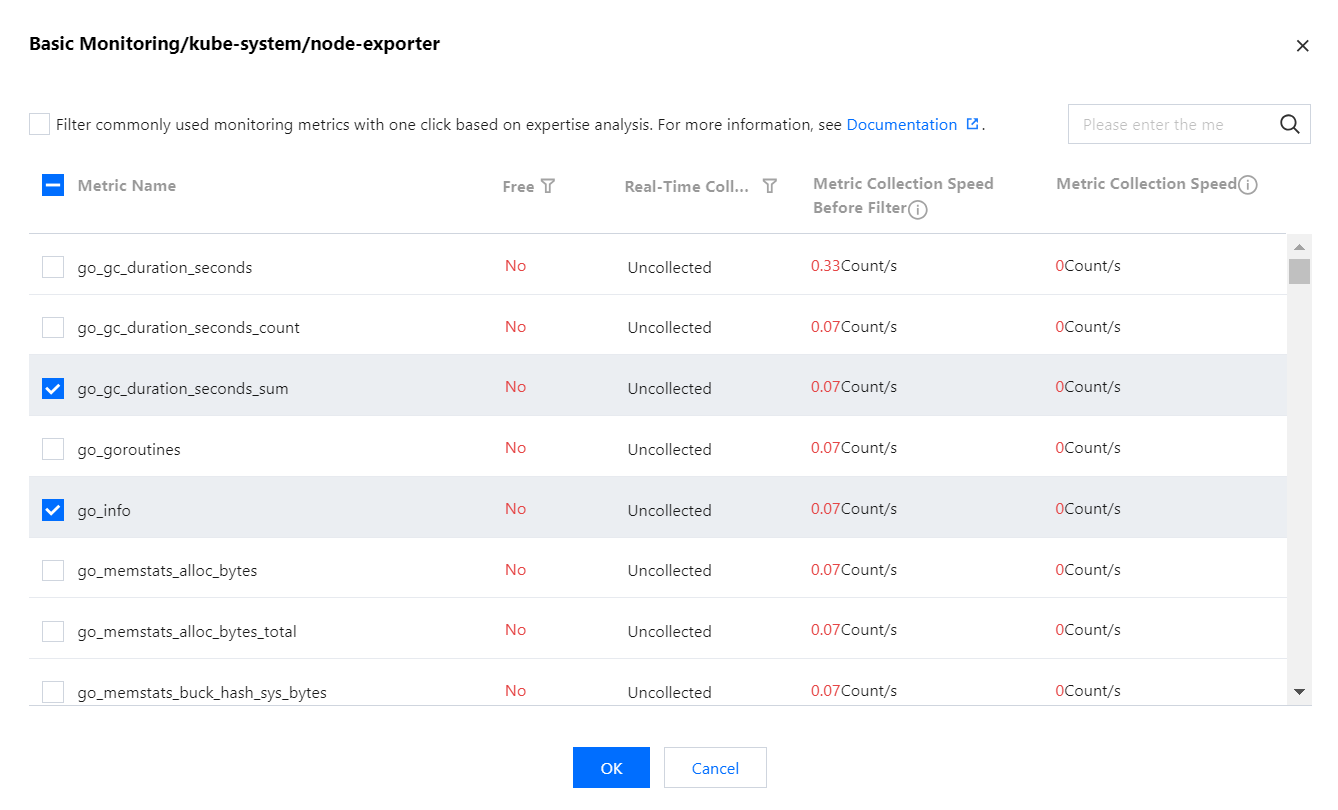
4. In the data collection configuration window, click Metric Details in the operation bar to deselect unnecessary metrics, as shown below:
5. On the page below, you can view free and billed metrics. If a metric is selected, corresponding data will be collected. You can select metrics as needed. Only basic monitoring provides free metrics. For all free metrics, see Free Metrics in Pay-as-You-Go Mode. For billing of paid metrics, see TMP Pay-as-You-Go.
Configuring Necessary Metrics via YAML File
The billing of TMP currently is based on the number of monitored data points. To minimize unnecessary expenses, it is recommended that you optimize the collection configuration to collect data of only necessary metrics, thereby reducing the overall data amount. For billing details and the usage of related cloud resources, see Resource Usage and Billing Overview.
The following part describes how to add filters to ServiceMonitor, PodMonitor, and native Job to configure necessary metrics.
2. On the instance list page, select the name of the instance that requires configuring data collection rules and enter its details page.
3. On the Data Collection page, click Integration with TKE, find the target cluster, and click Data Collection Configuration in the operation bar.
4. Find the target instance, and click Editing in the operation bar to view metric details.
ServiceMonitor and PodMonitor
Native Job
The filter configurations of ServiceMonitor and PodMonitor are the same. Take ServiceMonitor as an example.
ServiceMonitor example:
apiVersion: monitoring.coreos.com/v1
kind: ServiceMonitor
metadata:
labels:
app.kubernetes.io/name: kube-state-metrics
app.kubernetes.io/version: 1.9.7
name: kube-state-metrics
namespace: kube-system
spec:
endpoints:
- bearerTokenSecret:
key: ""
interval: 15s # This parameter indicates the collection interval. You can increase it to reduce data storage costs. For example, you can set the interval to 300s for less critical metrics, which can reduce the amount of collected monitoring data by 20 times.
port: http-metrics
scrapeTimeout: 15s # This parameter indicates the collection timeout. TMP requires that this timeout must not be longer than the collection interval. In other words, the value of scrapeTimeout should be no greater than that of interval.
jobLabel: app.kubernetes.io/name
namespaceSelector: {}
selector:
matchLabels:
app.kubernetes.io/name: kube-state-metrics
For example, if you want to collect data of metrics kube_node_info and kube_node_role, add the configuration with the metricRelabelings field to the endpoints list of ServiceMonitor. Note that the field is metricRelabelings, not relabelings.
Example of adding metricRelabelings:
apiVersion: monitoring.coreos.com/v1
kind: ServiceMonitor
metadata:
labels:
app.kubernetes.io/name: kube-state-metrics
app.kubernetes.io/version: 1.9.7
name: kube-state-metrics
namespace: kube-system
spec:
endpoints:
- bearerTokenSecret:
key: ""
interval: 15s # This parameter indicates the collection interval. You can increase it to reduce data storage costs. For example, you can set the interval to 300s for less critical metrics, which can reduce the amount of collected monitoring data by 20 times.
port: http-metrics
scrapeTimeout: 15s
# The following four lines are added:
metricRelabelings: # Each metric will undergo the following process.
- sourceLabels: ["__name__"] # The label name to be checked. __name__ refers to the metric name or any label of the metric.
regex: kube_node_info|kube_node_role # Check whether the label matches this regular expression. Here, __name__ is expected to match kube_node_info or kube_node_role.
action: keep # If the metric name meets the above conditions, the metric is kept. Otherwise, it is automatically discarded.
jobLabel: app.kubernetes.io/name
namespaceSelector: {}
selector:
If native Jobs of Prometheus are used, filter metrics using the method below.
Job example:
scrape_configs:
- job_name: job1
scrape_interval: 15s # This parameter indicates the collection interval. You can increase it to reduce data storage costs. For example, you can set the interval to 300s for less critical metrics, which can reduce the amount of collected monitoring data by 20 times.
static_configs:
- targets:
- '1.1.1.1'
For example, if you want to collect data of metrics kube_node_info and kube_node_role only, add the configuration with the field metric_relabel_configs. Note: The field is metric_relabel_configs, not relabel_configs.
Example of adding metric_relabel_configs:
scrape_configs:
- job_name: job1
scrape_interval: 15s # This parameter indicates the collection interval. You can increase it to reduce data storage costs. For example, you can set the interval to 300s for less critical metrics, which can reduce the amount of collected monitoring data by 20 times.
static_configs:
- targets:
- '1.1.1.1'
# The following four lines are added:
metric_relabel_configs: # Each metric will undergo the following process.
- source_labels: ["__name__"] # The label name to be checked. __name__ refers to the metric name or any label of the metric.
regex: kube_node_info|kube_node_role # Check whether the label matches this regular expression. Here, __name__ is expected to match kube_node_info or kube_node_role.
action: keep # If the metric name meets the above conditions, the metric is kept. Otherwise, it is automatically discarded.
5. Click Confirm.
Skipping Data Collection
Skipping Data Collection from Entire Namespace
TMP will manage all ServiceMonitors and PodMonitors in a cluster by default after the cluster is associated. If you want to skip data collection from a namespace, you can add the label tps-skip-monitor: "true" to the specified namespace. For label details, see Labels and Selectors.
Skipping Data Collection
TMP collects monitoring data by creating ServiceMonitor and PodMonitor types of CRD resources in a cluster. If you want to skip data collection from specified ServiceMonitor and PodMonitor resources, you can add the label tps-skip-monitor: "true" to these CRD resources. For label details, see Labels and Selectors.