- 初心者ガイド
- お知らせ・リリースノート
- 製品の動向
- パブリックイメージのリリースノート
- お知らせ
- CentOS 7用の一部のイメージ Pip パッケージ管理ツールの更新のお知らせ
- CentOS 8サポート終了についてのお知らせ
- SUSE商用版イメージのサポート終了のお知らせ
- 複数のアベイラビリティーゾーンのCVM価格改定(値下げ)のお知らせ
- OrcaTermプロキシIPアドレスの更新についてのお知らせ
- シリコンバレー地域の標準型S3 CVMの価格調整
- Tencent Cloudの Linux イメージ長期脆弱性のリカバリポリシーのお知らせ
- Ubuntu10.04イメージのオフラインおよび既存リポジトリ設定に関するお知らせ
- Ubuntu14.04 が Tomcat を起動できないのソリューションについてのお知らせ
- Windows のCVMが Virtio ENIドライバーをアップグレードすることについてのお知らせ
- セキュリティグループの53ポートの設定に関するお知らせ
- Windows Server 2003 システムイメージをサポートしないことについてのお知らせ
- Windows Server 2008 R2 Enterprise Edition SP1 64ビットシステムイメージのサポート終了のお知らせ
- 製品紹介
- 購入ガイド
- クイックスタート
- 操作ガイド
- 操作ガイド一覧
- ご利用制限一覧
- 便利な機能
- インスタンス
- インスタンスを作成
- インスタンス起動テンプレートの管理
- 一括連続命名または指定文字列パターン命名
- Linuxインスタンスにログインする
- Windowsインスタンスにログインする
- 設定を調整する
- 情報の確認
- インスタンスの名前変更
- インスタンスのパスワードのリセット方法
- インスタンス IP アドレスを管理する
- セキュリティグループの変更
- 従量課金インスタンスの年額・月額課金への変換
- インスタンスの検索
- インスタンスリストのエクスポート
- インスタンスの起動
- インスタンスのシャットダウン
- インスタンスの再起動
- インスタンスの休止
- システムをリインストールする
- TATを使用してコマンドを実行し
- インスタンスの破棄/返却
- インスタンスの削除保護の有効化
- インスタンスを回収する又はインスタンスの復元
- スポットインスタンスの管理
- スポットインスタンスの回収状態を確認する
- 停止済み従量課金インスタンスの非課金化
- インスタンスロールの管理
- リザーブドインスタンス
- イメージ
- サービス移行
- メンテナンスタスク
- Cloud Block Storage
- ネットワーク
- セキュリティ
- タグ
- 監視とアラーム
- Cloud Access Managementの例
- プラクティスチュートリアル
- CVMに対する最高実践
- CVMタイプ選択のベストプラクティス
- ウェブサイトの構築方法
- 環境構築
- ウェブサイトの構築
- アプリケーションの構築
- ビジュアルインターフェイスを作成
- データバックアップ
- ローカルファイルをCVMにアップロードします
- ローカルファイルをCVMにコピーする方法
- WindowsシステムはMSTSCを介してWindows CVMにファイルをアップロードします
- MRDを介してMacOSからWindows CVMにファイルをアップロード
- LinuxシステムはRDPを介してWindows CVMにファイルをアップロードします
- WinSCPを介してWindowsからLinux CVMにファイルをアップロード
- LinuxまたはMacOSマシンでSCPを介してファイルをLinux CVMにアップロード
- LinuxシステムはFTP経由でファイルをCVMにアップロード
- Windows OSからFTPを利用して、CVMにファイルをアップロードする
- その他のCVM操作
- CVMのプライベートネットワークによるCOSへのアクセス
- Linux CVMでのデータリカバリ
- Windows CVMでのディスク容量の管理
- Linuxインスタンスのカーネルを手動で変更する
- Cloud Virtual MachineによるWindowsシステムのADドメインの構築
- ネットワーク性能のテスト
- 高スループットネットワークパフォーマンステスト
- LinuxでUSB/IPを使用してUSBデバイスを共有する
- Windowsインスタンス:CPUまたはメモリの使用率が高いため、CVMにログインできない
- CVMでAVX512を介して人工知能アプリケーションをアクセラレーションします
- Tencent SGXコンフィデンシャル・コンピューティング環境の構築
- M6pインスタンスによる永続メモリの構成
- Python 経由でクラウド API を呼び出してカスタムイメージを一括共有
- メンテナンスガイド
- トラブルシューティング
- インスタンス関連障害
- CVMインスタンスにログインできない原因や対処法
- Windowsインスタンス関連
- Windows のインスタンスにログインできない
- Windowsインスタンス:認証エラーが発生した
- CVMパスワードリセット失敗、またはパスワードが無効
- Windows インスタンス:リモートデスクトップサービスを使ったログオンを拒否
- Windowsインスタンス:ネットワークレベルの認証が必要
- Windowsインスタンス:Macリモートログイン異常
- Windowsインスタンス:CPUまたはメモリの使用率が高いためログインできない
- Windowsインスタンス:リモートデスクトップでリモートパソコンに接続できない
- Windowsインスタンス:お使いの資格情報は機能しませんでした
- Windows インスタンス:ポート問題が原因でリモートログインできない
- Linuxインスタンス関連
- Linuxインスタンス登録失敗
- LinuxインスタンスをSSHで登録できない
- Linuxインスタンス:CPUまたはメモリの使用率が高いためログインできない
- Linuxインスタンス:ポートの問題によるログインができない
- Linuxインスタンス:VNCログインエラー Module is unknown
- Linuxインスタンス:VNCログインエラー Account locked due to XXX failed logins
- Linuxインスタンス:VNCへのログインに正しいパスワードを入力しても応答がありません
- Linuxインスタンス:VNCまたはSSHログインエラー Permission denied
- Linuxインスタンス:/etc/fstabの設定エラーによるログイン不能
- Linuxインスタンス:sshd設定ファイル権限に関する問題
- Linuxインスタンス:/etc/profile コールが無限ループする場合
- サーバーが隔離されたためログインできない
- 帯域幅の利用率が高いためログインできない
- セキュリティグループの設定が原因でリモート接続できない
- LinuxインスタンスのVNC使用およびレスキューモードを使用したトラブルシューティング
- CVMの再起動またはシャットダウンは失敗しましたの原因と対処
- Network Namespaceを作成できない
- カーネルおよび IO 関連問題
- システムbinまたはlibソフトリンクの欠如
- CVMにウイルス侵入が疑われる場合
- ファイル作成のエラー no space left on device
- ネットワーク関連の故障
- インスタンス関連障害
- API リファレンス
- History
- Introduction
- API Category
- Region APIs
- Instance APIs
- RunInstances
- DescribeInstances
- DescribeInstanceFamilyConfigs
- DescribeInstancesOperationLimit
- InquiryPriceRunInstances
- InquiryPriceResetInstance
- InquiryPriceResetInstancesType
- StartInstances
- RebootInstances
- StopInstances
- ResizeInstanceDisks
- ResetInstancesPassword
- ModifyInstancesAttribute
- EnterRescueMode
- ExitRescueMode
- InquirePricePurchaseReservedInstancesOffering
- InquiryPriceResizeInstanceDisks
- TerminateInstances
- ModifyInstancesProject
- ResetInstancesType
- DescribeInstancesStatus
- DescribeReservedInstancesConfigInfos
- DescribeZoneInstanceConfigInfos
- PurchaseReservedInstancesOffering
- ResetInstance
- DescribeInstanceTypeConfigs
- DescribeInstanceVncUrl
- Cloud Hosting Cluster APIs
- Image APIs
- Instance Launch Template APIs
- Making API Requests
- Placement Group APIs
- Key APIs
- Security Group APIs
- Network APIs
- Data Types
- Error Codes
- よくある質問
- Related Agreement
- 用語表
- 初心者ガイド
- お知らせ・リリースノート
- 製品の動向
- パブリックイメージのリリースノート
- お知らせ
- CentOS 7用の一部のイメージ Pip パッケージ管理ツールの更新のお知らせ
- CentOS 8サポート終了についてのお知らせ
- SUSE商用版イメージのサポート終了のお知らせ
- 複数のアベイラビリティーゾーンのCVM価格改定(値下げ)のお知らせ
- OrcaTermプロキシIPアドレスの更新についてのお知らせ
- シリコンバレー地域の標準型S3 CVMの価格調整
- Tencent Cloudの Linux イメージ長期脆弱性のリカバリポリシーのお知らせ
- Ubuntu10.04イメージのオフラインおよび既存リポジトリ設定に関するお知らせ
- Ubuntu14.04 が Tomcat を起動できないのソリューションについてのお知らせ
- Windows のCVMが Virtio ENIドライバーをアップグレードすることについてのお知らせ
- セキュリティグループの53ポートの設定に関するお知らせ
- Windows Server 2003 システムイメージをサポートしないことについてのお知らせ
- Windows Server 2008 R2 Enterprise Edition SP1 64ビットシステムイメージのサポート終了のお知らせ
- 製品紹介
- 購入ガイド
- クイックスタート
- 操作ガイド
- 操作ガイド一覧
- ご利用制限一覧
- 便利な機能
- インスタンス
- インスタンスを作成
- インスタンス起動テンプレートの管理
- 一括連続命名または指定文字列パターン命名
- Linuxインスタンスにログインする
- Windowsインスタンスにログインする
- 設定を調整する
- 情報の確認
- インスタンスの名前変更
- インスタンスのパスワードのリセット方法
- インスタンス IP アドレスを管理する
- セキュリティグループの変更
- 従量課金インスタンスの年額・月額課金への変換
- インスタンスの検索
- インスタンスリストのエクスポート
- インスタンスの起動
- インスタンスのシャットダウン
- インスタンスの再起動
- インスタンスの休止
- システムをリインストールする
- TATを使用してコマンドを実行し
- インスタンスの破棄/返却
- インスタンスの削除保護の有効化
- インスタンスを回収する又はインスタンスの復元
- スポットインスタンスの管理
- スポットインスタンスの回収状態を確認する
- 停止済み従量課金インスタンスの非課金化
- インスタンスロールの管理
- リザーブドインスタンス
- イメージ
- サービス移行
- メンテナンスタスク
- Cloud Block Storage
- ネットワーク
- セキュリティ
- タグ
- 監視とアラーム
- Cloud Access Managementの例
- プラクティスチュートリアル
- CVMに対する最高実践
- CVMタイプ選択のベストプラクティス
- ウェブサイトの構築方法
- 環境構築
- ウェブサイトの構築
- アプリケーションの構築
- ビジュアルインターフェイスを作成
- データバックアップ
- ローカルファイルをCVMにアップロードします
- ローカルファイルをCVMにコピーする方法
- WindowsシステムはMSTSCを介してWindows CVMにファイルをアップロードします
- MRDを介してMacOSからWindows CVMにファイルをアップロード
- LinuxシステムはRDPを介してWindows CVMにファイルをアップロードします
- WinSCPを介してWindowsからLinux CVMにファイルをアップロード
- LinuxまたはMacOSマシンでSCPを介してファイルをLinux CVMにアップロード
- LinuxシステムはFTP経由でファイルをCVMにアップロード
- Windows OSからFTPを利用して、CVMにファイルをアップロードする
- その他のCVM操作
- CVMのプライベートネットワークによるCOSへのアクセス
- Linux CVMでのデータリカバリ
- Windows CVMでのディスク容量の管理
- Linuxインスタンスのカーネルを手動で変更する
- Cloud Virtual MachineによるWindowsシステムのADドメインの構築
- ネットワーク性能のテスト
- 高スループットネットワークパフォーマンステスト
- LinuxでUSB/IPを使用してUSBデバイスを共有する
- Windowsインスタンス:CPUまたはメモリの使用率が高いため、CVMにログインできない
- CVMでAVX512を介して人工知能アプリケーションをアクセラレーションします
- Tencent SGXコンフィデンシャル・コンピューティング環境の構築
- M6pインスタンスによる永続メモリの構成
- Python 経由でクラウド API を呼び出してカスタムイメージを一括共有
- メンテナンスガイド
- トラブルシューティング
- インスタンス関連障害
- CVMインスタンスにログインできない原因や対処法
- Windowsインスタンス関連
- Windows のインスタンスにログインできない
- Windowsインスタンス:認証エラーが発生した
- CVMパスワードリセット失敗、またはパスワードが無効
- Windows インスタンス:リモートデスクトップサービスを使ったログオンを拒否
- Windowsインスタンス:ネットワークレベルの認証が必要
- Windowsインスタンス:Macリモートログイン異常
- Windowsインスタンス:CPUまたはメモリの使用率が高いためログインできない
- Windowsインスタンス:リモートデスクトップでリモートパソコンに接続できない
- Windowsインスタンス:お使いの資格情報は機能しませんでした
- Windows インスタンス:ポート問題が原因でリモートログインできない
- Linuxインスタンス関連
- Linuxインスタンス登録失敗
- LinuxインスタンスをSSHで登録できない
- Linuxインスタンス:CPUまたはメモリの使用率が高いためログインできない
- Linuxインスタンス:ポートの問題によるログインができない
- Linuxインスタンス:VNCログインエラー Module is unknown
- Linuxインスタンス:VNCログインエラー Account locked due to XXX failed logins
- Linuxインスタンス:VNCへのログインに正しいパスワードを入力しても応答がありません
- Linuxインスタンス:VNCまたはSSHログインエラー Permission denied
- Linuxインスタンス:/etc/fstabの設定エラーによるログイン不能
- Linuxインスタンス:sshd設定ファイル権限に関する問題
- Linuxインスタンス:/etc/profile コールが無限ループする場合
- サーバーが隔離されたためログインできない
- 帯域幅の利用率が高いためログインできない
- セキュリティグループの設定が原因でリモート接続できない
- LinuxインスタンスのVNC使用およびレスキューモードを使用したトラブルシューティング
- CVMの再起動またはシャットダウンは失敗しましたの原因と対処
- Network Namespaceを作成できない
- カーネルおよび IO 関連問題
- システムbinまたはlibソフトリンクの欠如
- CVMにウイルス侵入が疑われる場合
- ファイル作成のエラー no space left on device
- ネットワーク関連の故障
- インスタンス関連障害
- API リファレンス
- History
- Introduction
- API Category
- Region APIs
- Instance APIs
- RunInstances
- DescribeInstances
- DescribeInstanceFamilyConfigs
- DescribeInstancesOperationLimit
- InquiryPriceRunInstances
- InquiryPriceResetInstance
- InquiryPriceResetInstancesType
- StartInstances
- RebootInstances
- StopInstances
- ResizeInstanceDisks
- ResetInstancesPassword
- ModifyInstancesAttribute
- EnterRescueMode
- ExitRescueMode
- InquirePricePurchaseReservedInstancesOffering
- InquiryPriceResizeInstanceDisks
- TerminateInstances
- ModifyInstancesProject
- ResetInstancesType
- DescribeInstancesStatus
- DescribeReservedInstancesConfigInfos
- DescribeZoneInstanceConfigInfos
- PurchaseReservedInstancesOffering
- ResetInstance
- DescribeInstanceTypeConfigs
- DescribeInstanceVncUrl
- Cloud Hosting Cluster APIs
- Image APIs
- Instance Launch Template APIs
- Making API Requests
- Placement Group APIs
- Key APIs
- Security Group APIs
- Network APIs
- Data Types
- Error Codes
- よくある質問
- Related Agreement
- 用語表
クラウドネイティブのシナリオでは、Namespace と Cgroup がリソース隔離の基本的なサポートを提供しますが、コンテナの全体的な隔離機能はまだ不完全です。特に、/proc と /sys ファイルシステムにおける一部のリソース統計はコンテナ化されていないため、コンテナ内で実行される一般的なコマンド(free、top など)がコンテナリソースの使用状況を正確に表示することができません。
この問題に対して、TencentOS カーネルは、コンテナリソースの表示を改善するための cgroupfs ソリューションを導入しています。cgroupfs は、ビジネスに必要な、コンテナ視点の /proc と /sys などのファイルを含む仮想ファイルシステムを実装し、ユーザーツールとの互換性を確保するために、グローバルな procfs と sysfs と一貫性のあるディレクトリ構造になっています。これらのファイルが実際に読み込まれると、cgroupfs はリーダープロセスのコンテキストから適切なコンテナ情報ビューを動的に生成します。
cgroupfsファイルシステムのマウント
1. 以下のコマンドを実行することで、cgroupfs ファイルシステムをマウントします。
mount -t cgroupfs cgroupfs /cgroupfs/
スクリーンショットは以下のとおりです。
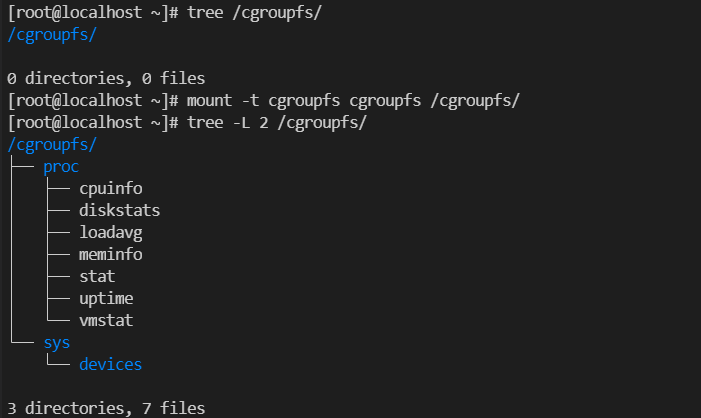
2.
-vオプションを使用すると、必要に応じてcgroupfs 配下のファイルを指定したコンテナにマウントします。docker の起動コマンドは以下のとおりです。docker run -itd --cpus 2 --cpuset-cpus 0,1,2,4 -v/cgroupfs/sys/devices/system/cpu/:/sys/devices/system/cpu -v/cgroupfs/proc/cpuinfo:/proc/cpuinfo -v/cgroupfs/proc/stat:/proc/stat -v/cgroupfs/proc/meminfo:/proc/meminfo <image-id> /bin/bash
3. その後、コンテナ視点の cpuinfo、stat、meminfo の情報のみは、コンテナ内で表示されます。
pagecache 隔離
プロセスファイルページの使用が過剰になると、大量のメモリを占有することになり、その結果、他のビジネスに使用できるメモリが減少します。このような状況では、マシンのメモリ割り当てが頻繁に非効率な経路に陥り、メモリ不足(OOM)エラーが発生しやすくなります。クラウドネイティブのシナリオでは、カーネルのページキャッシュ(page cache)を拡張してコンテナのページキャッシュ使用量の制限を実現することで、コンテナのページキャッシュ使用量を個別に制限できるようにしています。
マシン全体の pagecache 制限:
sysctl -w vm.memory_qos=1sysctl -w vm.pagecache_limit_global=1
echo x > /proc/sys/vm/pagecache_limit_ratio#(0 < x < 100)page cache limit 制限を有効にします。30 などの 0 以外の場合は、 page cache がシステムメモリ全体の 30% に制限されることを示します。
ダーティページのリサイクルは比較的時間がかかります。
pagecache_limit_ignore_dirtyは、 page cache の占有メモリを計算する際にダーティページを無視するかどうかを決定するために使用されます。 その位置は以下の通りです。/proc/sys/vm/pagecache_limit_ignore_dirty。デフォルト値は 1 であり、これはダーティなページを無視することを示します。
page cache のリサイクル方法の設定:
/proc/sys/vm/pagecache_limit_async
1 は page cache を非同期にリサイクルすることを示します。TencentOS は page cache のリサイクルを処理する [kpclimitd] カーネルスレッドを作成します。
0 は同期的なリサイクルを示し、専用のリサイクルスレッドは作成されず、page cache limit によってトリガされたプロセスのコンテキストで直接リサイクルされます。デフォルト値は 0 です。
コンテナの pagecache 制限:
グローバルシステムレベルの pagecache 制限に加え、TencentOS はコンテナレベルの pagecache 制限をもサポートしています。利用方法は以下のとおりです。
1. メモリ QOS を有効にする:
sysctl -w vm.memory_qos=1
2. グローバル pagecache 制限を無効にする:
sysctl -w vm.pagecache_limit_global=0
3. コンテナが所在している memcg に移動し、memory 制限を設定します。
echo value > memory.limit_in_bytes
4. pagecache の最大使用量を、現在のメモリ制限のパーセンテージに設定します。例えば、10% を設定します。
echo 10 > memory.pagecache.max_ratio
5. pagecache が制限を超過した場合のリサイクル比率を設定します。
echo 5 > memory.pagecache.reclaim_ratio
読み取りと書き込みの速度制限を統一する
Linux カーネル固有の IO 速度制限方式は、読み取りと書き込みを分離しているため、管理者はビジネスモデルに従って IO 帯域幅を分割し、読み取りと書き込みを分離した方式で速度制限を実施する必要がありますので、帯域幅の浪費という問題があります。例えば、設定が読み取り 50MB/秒、書き込み 50MB/秒であっても、実際の IO 帯域幅が読み取り 20MB/秒、書き込み 50MB/秒であれば、読み取り 30MB/秒の帯域幅が浪費されてしまうのです。この問題を解決するために、TencentOS は読み書きの統一速度制限のソリューションを導入しました。TencentOS は、読込みと書込みの速度制限を統一する設定インタフェースをユーザーに提供し、カーネルの状態では、業務トラフィックに応じて読込みと書込みの比率を動的に分割します。 使い方は以下の通りです。
ビジネスに対応する blkio が所在している cgroup に入り、echo MAJ:MIN VAL > FILE という設定を使用します。
ここで、MAJ:MIN はデバイス番号を示し、FILE と VAL は以下の表に示されています。
FILE | VAL |
blkio.throttle.readwrite_bps_device | 読み書き Bps の合計制限値 |
blkio.throttle.readwrite_iops_device | 読み書き iops の合計制限 |
blkio.throttle.readwrite_dynamic_ratio | 読み書き比率の動的予測: 0:無効にします。 固定(読み:書き - 3:1)比率を使用します 1~5:動的予測方式を有効にします。 |
buffer io 速度制限のサポート
Linux ネイティブカーネルでは、cgroup v1 は buffer IO の速度制限において幾つかの欠点があります。Buffer IO のライトバックは通常非同期プロセスであり、カーネルは、非同期ダーティフラッシュ操作中に IO をどの blkio cgroup に送信すべきかを判断できないため、適切な blkio 速度制限ポリシーを適用できません。
これを踏まえ、TencentOS は cgroup v1 の buffer IO 速度制限機能をさらに改善し、cgroup v2 に基づく buffer IO 速度制限機能と一致するようにしました。cgroup v1 については、page cache の mem_cgroup を対応する blkio cgroup にバインディングできるユーザーモードインターフェースを提供することで、カーネルがバインディング情報に基づいて buffer IO の速度制限を行えるようにしました。
1. buffer IO の速度制限を有効にするには、kernel.io_qos と kernel.io_cgv1_buff_wb の 2 つの特性を有効にする必要があります。
sysctl -w kernel.io_qos=1 # IO QoS 特性を有効にします sysctl -w kernel.io_cgv1_buff_wb=1 # Buffer IO 特性を有効にします(デフォルトで有効にする)
2. コンテナの buffer I/O 速度制限を実装するには、コンテナに対応する memcg を blkcg の cgroup に明示的にバインディングする必要があります。操作は以下の通りです。
echo /sys/fs/cgroup/blkio/A > /sys/fs/cgroup/memory/A/memory.bind_blkio
バインディングすると、コンテナのバッファI/Oリソースに対してblkio cgroup によって提供される制限メカニズムは、以下のインターフェイスで表示することができます。
blkio.throttle.read_bps_device
blkio.throttle.write_bps_device
blkio.throttle.write_iops_device
blkio.throttle.read_iops_device
blkio.throttle.readwrite_bps_device
blkio.throttle.readwrite_iops_device
非同期 fork
大容量メモリのビジネスがサブプロセスを作成するために fork システムコールを実行する場合、fork 呼び出しには比較的長い時間がかかり、ビジネスがカーネル状態に長時間とどまることで、ビジネスリクエストを処理できない可能性があります。 そのため、このシナリオではカーネルの fork 時間を最適化する必要があります。
Linux では、カーネルで fork を処理するデフォルトプロセスにおいて、親プロセスが子プロセスに大量のプロセスメタデータをコピーする必要があります。そのうち、ページテーブルが最も時間のかかる部分であり、通常、fork 呼び出しにかかる時間の 97% 以上を占めます。非同期 fork を設計する考え方は、ページテーブルをコピーする作業を親プロセスから子プロセスに移すことで、親プロセスが fork システムコールを呼び出してカーネル状態に陥るまでの時間を短縮し、アプリケーションはできるだけ早くユーザーモードに戻ってビジネスリクエストを処理することができるため、fork に起因するパフォーマンスジッターの問題を解決できます。
この機能は
cgroupを介してスイッチ制御を行います。基本的な使い方は以下の通りです。echo 1 > <cgroup ディレクトリ>/memory.async_fork # 現在の cgroup ディレクトリの 非同期 fork 機能を有効にします echo 0 > <cgroup目录>/memory.async_fork #現在の cgroup ディレクトリの非同期 fork 機能を無効にします
このインターフェースのデフォルト値は 0 です。つまり、デフォルトで無効になります。

 はい
はい
 いいえ
いいえ
この記事はお役に立ちましたか?