- 初心者ガイド
- お知らせ・リリースノート
- 製品の動向
- パブリックイメージのリリースノート
- お知らせ
- CentOS 7用の一部のイメージ Pip パッケージ管理ツールの更新のお知らせ
- CentOS 8サポート終了についてのお知らせ
- SUSE商用版イメージのサポート終了のお知らせ
- 複数のアベイラビリティーゾーンのCVM価格改定(値下げ)のお知らせ
- OrcaTermプロキシIPアドレスの更新についてのお知らせ
- シリコンバレー地域の標準型S3 CVMの価格調整
- Tencent Cloudの Linux イメージ長期脆弱性のリカバリポリシーのお知らせ
- Ubuntu10.04イメージのオフラインおよび既存リポジトリ設定に関するお知らせ
- Ubuntu14.04 が Tomcat を起動できないのソリューションについてのお知らせ
- Windows のCVMが Virtio ENIドライバーをアップグレードすることについてのお知らせ
- セキュリティグループの53ポートの設定に関するお知らせ
- Windows Server 2003 システムイメージをサポートしないことについてのお知らせ
- Windows Server 2008 R2 Enterprise Edition SP1 64ビットシステムイメージのサポート終了のお知らせ
- 製品紹介
- 購入ガイド
- クイックスタート
- 操作ガイド
- 操作ガイド一覧
- ご利用制限一覧
- 便利な機能
- インスタンス
- インスタンスを作成
- インスタンス起動テンプレートの管理
- 一括連続命名または指定文字列パターン命名
- Linuxインスタンスにログインする
- Windowsインスタンスにログインする
- 設定を調整する
- 情報の確認
- インスタンスの名前変更
- インスタンスのパスワードのリセット方法
- インスタンス IP アドレスを管理する
- セキュリティグループの変更
- 従量課金インスタンスの年額・月額課金への変換
- インスタンスの検索
- インスタンスリストのエクスポート
- インスタンスの起動
- インスタンスのシャットダウン
- インスタンスの再起動
- インスタンスの休止
- システムをリインストールする
- TATを使用してコマンドを実行し
- インスタンスの破棄/返却
- インスタンスの削除保護の有効化
- インスタンスを回収する又はインスタンスの復元
- スポットインスタンスの管理
- スポットインスタンスの回収状態を確認する
- 停止済み従量課金インスタンスの非課金化
- インスタンスロールの管理
- リザーブドインスタンス
- イメージ
- サービス移行
- メンテナンスタスク
- Cloud Block Storage
- ネットワーク
- セキュリティ
- タグ
- 監視とアラーム
- Cloud Access Managementの例
- プラクティスチュートリアル
- CVMに対する最高実践
- CVMタイプ選択のベストプラクティス
- ウェブサイトの構築方法
- 環境構築
- ウェブサイトの構築
- アプリケーションの構築
- ビジュアルインターフェイスを作成
- データバックアップ
- ローカルファイルをCVMにアップロードします
- ローカルファイルをCVMにコピーする方法
- WindowsシステムはMSTSCを介してWindows CVMにファイルをアップロードします
- MRDを介してMacOSからWindows CVMにファイルをアップロード
- LinuxシステムはRDPを介してWindows CVMにファイルをアップロードします
- WinSCPを介してWindowsからLinux CVMにファイルをアップロード
- LinuxまたはMacOSマシンでSCPを介してファイルをLinux CVMにアップロード
- LinuxシステムはFTP経由でファイルをCVMにアップロード
- Windows OSからFTPを利用して、CVMにファイルをアップロードする
- その他のCVM操作
- CVMのプライベートネットワークによるCOSへのアクセス
- Linux CVMでのデータリカバリ
- Windows CVMでのディスク容量の管理
- Linuxインスタンスのカーネルを手動で変更する
- Cloud Virtual MachineによるWindowsシステムのADドメインの構築
- ネットワーク性能のテスト
- 高スループットネットワークパフォーマンステスト
- LinuxでUSB/IPを使用してUSBデバイスを共有する
- Windowsインスタンス:CPUまたはメモリの使用率が高いため、CVMにログインできない
- CVMでAVX512を介して人工知能アプリケーションをアクセラレーションします
- Tencent SGXコンフィデンシャル・コンピューティング環境の構築
- M6pインスタンスによる永続メモリの構成
- Python 経由でクラウド API を呼び出してカスタムイメージを一括共有
- メンテナンスガイド
- トラブルシューティング
- インスタンス関連障害
- CVMインスタンスにログインできない原因や対処法
- Windowsインスタンス関連
- Windows のインスタンスにログインできない
- Windowsインスタンス:認証エラーが発生した
- CVMパスワードリセット失敗、またはパスワードが無効
- Windows インスタンス:リモートデスクトップサービスを使ったログオンを拒否
- Windowsインスタンス:ネットワークレベルの認証が必要
- Windowsインスタンス:Macリモートログイン異常
- Windowsインスタンス:CPUまたはメモリの使用率が高いためログインできない
- Windowsインスタンス:リモートデスクトップでリモートパソコンに接続できない
- Windowsインスタンス:お使いの資格情報は機能しませんでした
- Windows インスタンス:ポート問題が原因でリモートログインできない
- Linuxインスタンス関連
- Linuxインスタンス登録失敗
- LinuxインスタンスをSSHで登録できない
- Linuxインスタンス:CPUまたはメモリの使用率が高いためログインできない
- Linuxインスタンス:ポートの問題によるログインができない
- Linuxインスタンス:VNCログインエラー Module is unknown
- Linuxインスタンス:VNCログインエラー Account locked due to XXX failed logins
- Linuxインスタンス:VNCへのログインに正しいパスワードを入力しても応答がありません
- Linuxインスタンス:VNCまたはSSHログインエラー Permission denied
- Linuxインスタンス:/etc/fstabの設定エラーによるログイン不能
- Linuxインスタンス:sshd設定ファイル権限に関する問題
- Linuxインスタンス:/etc/profile コールが無限ループする場合
- サーバーが隔離されたためログインできない
- 帯域幅の利用率が高いためログインできない
- セキュリティグループの設定が原因でリモート接続できない
- LinuxインスタンスのVNC使用およびレスキューモードを使用したトラブルシューティング
- CVMの再起動またはシャットダウンは失敗しましたの原因と対処
- Network Namespaceを作成できない
- カーネルおよび IO 関連問題
- システムbinまたはlibソフトリンクの欠如
- CVMにウイルス侵入が疑われる場合
- ファイル作成のエラー no space left on device
- ネットワーク関連の故障
- インスタンス関連障害
- API リファレンス
- History
- Introduction
- API Category
- Region APIs
- Instance APIs
- RunInstances
- DescribeInstances
- DescribeInstanceFamilyConfigs
- DescribeInstancesOperationLimit
- InquiryPriceRunInstances
- InquiryPriceResetInstance
- InquiryPriceResetInstancesType
- StartInstances
- RebootInstances
- StopInstances
- ResizeInstanceDisks
- ResetInstancesPassword
- ModifyInstancesAttribute
- EnterRescueMode
- ExitRescueMode
- InquirePricePurchaseReservedInstancesOffering
- InquiryPriceResizeInstanceDisks
- TerminateInstances
- ModifyInstancesProject
- ResetInstancesType
- DescribeInstancesStatus
- DescribeReservedInstancesConfigInfos
- DescribeZoneInstanceConfigInfos
- PurchaseReservedInstancesOffering
- ResetInstance
- DescribeInstanceTypeConfigs
- DescribeInstanceVncUrl
- Cloud Hosting Cluster APIs
- Image APIs
- Instance Launch Template APIs
- Making API Requests
- Placement Group APIs
- Key APIs
- Security Group APIs
- Network APIs
- Data Types
- Error Codes
- よくある質問
- Related Agreement
- 用語表
- 初心者ガイド
- お知らせ・リリースノート
- 製品の動向
- パブリックイメージのリリースノート
- お知らせ
- CentOS 7用の一部のイメージ Pip パッケージ管理ツールの更新のお知らせ
- CentOS 8サポート終了についてのお知らせ
- SUSE商用版イメージのサポート終了のお知らせ
- 複数のアベイラビリティーゾーンのCVM価格改定(値下げ)のお知らせ
- OrcaTermプロキシIPアドレスの更新についてのお知らせ
- シリコンバレー地域の標準型S3 CVMの価格調整
- Tencent Cloudの Linux イメージ長期脆弱性のリカバリポリシーのお知らせ
- Ubuntu10.04イメージのオフラインおよび既存リポジトリ設定に関するお知らせ
- Ubuntu14.04 が Tomcat を起動できないのソリューションについてのお知らせ
- Windows のCVMが Virtio ENIドライバーをアップグレードすることについてのお知らせ
- セキュリティグループの53ポートの設定に関するお知らせ
- Windows Server 2003 システムイメージをサポートしないことについてのお知らせ
- Windows Server 2008 R2 Enterprise Edition SP1 64ビットシステムイメージのサポート終了のお知らせ
- 製品紹介
- 購入ガイド
- クイックスタート
- 操作ガイド
- 操作ガイド一覧
- ご利用制限一覧
- 便利な機能
- インスタンス
- インスタンスを作成
- インスタンス起動テンプレートの管理
- 一括連続命名または指定文字列パターン命名
- Linuxインスタンスにログインする
- Windowsインスタンスにログインする
- 設定を調整する
- 情報の確認
- インスタンスの名前変更
- インスタンスのパスワードのリセット方法
- インスタンス IP アドレスを管理する
- セキュリティグループの変更
- 従量課金インスタンスの年額・月額課金への変換
- インスタンスの検索
- インスタンスリストのエクスポート
- インスタンスの起動
- インスタンスのシャットダウン
- インスタンスの再起動
- インスタンスの休止
- システムをリインストールする
- TATを使用してコマンドを実行し
- インスタンスの破棄/返却
- インスタンスの削除保護の有効化
- インスタンスを回収する又はインスタンスの復元
- スポットインスタンスの管理
- スポットインスタンスの回収状態を確認する
- 停止済み従量課金インスタンスの非課金化
- インスタンスロールの管理
- リザーブドインスタンス
- イメージ
- サービス移行
- メンテナンスタスク
- Cloud Block Storage
- ネットワーク
- セキュリティ
- タグ
- 監視とアラーム
- Cloud Access Managementの例
- プラクティスチュートリアル
- CVMに対する最高実践
- CVMタイプ選択のベストプラクティス
- ウェブサイトの構築方法
- 環境構築
- ウェブサイトの構築
- アプリケーションの構築
- ビジュアルインターフェイスを作成
- データバックアップ
- ローカルファイルをCVMにアップロードします
- ローカルファイルをCVMにコピーする方法
- WindowsシステムはMSTSCを介してWindows CVMにファイルをアップロードします
- MRDを介してMacOSからWindows CVMにファイルをアップロード
- LinuxシステムはRDPを介してWindows CVMにファイルをアップロードします
- WinSCPを介してWindowsからLinux CVMにファイルをアップロード
- LinuxまたはMacOSマシンでSCPを介してファイルをLinux CVMにアップロード
- LinuxシステムはFTP経由でファイルをCVMにアップロード
- Windows OSからFTPを利用して、CVMにファイルをアップロードする
- その他のCVM操作
- CVMのプライベートネットワークによるCOSへのアクセス
- Linux CVMでのデータリカバリ
- Windows CVMでのディスク容量の管理
- Linuxインスタンスのカーネルを手動で変更する
- Cloud Virtual MachineによるWindowsシステムのADドメインの構築
- ネットワーク性能のテスト
- 高スループットネットワークパフォーマンステスト
- LinuxでUSB/IPを使用してUSBデバイスを共有する
- Windowsインスタンス:CPUまたはメモリの使用率が高いため、CVMにログインできない
- CVMでAVX512を介して人工知能アプリケーションをアクセラレーションします
- Tencent SGXコンフィデンシャル・コンピューティング環境の構築
- M6pインスタンスによる永続メモリの構成
- Python 経由でクラウド API を呼び出してカスタムイメージを一括共有
- メンテナンスガイド
- トラブルシューティング
- インスタンス関連障害
- CVMインスタンスにログインできない原因や対処法
- Windowsインスタンス関連
- Windows のインスタンスにログインできない
- Windowsインスタンス:認証エラーが発生した
- CVMパスワードリセット失敗、またはパスワードが無効
- Windows インスタンス:リモートデスクトップサービスを使ったログオンを拒否
- Windowsインスタンス:ネットワークレベルの認証が必要
- Windowsインスタンス:Macリモートログイン異常
- Windowsインスタンス:CPUまたはメモリの使用率が高いためログインできない
- Windowsインスタンス:リモートデスクトップでリモートパソコンに接続できない
- Windowsインスタンス:お使いの資格情報は機能しませんでした
- Windows インスタンス:ポート問題が原因でリモートログインできない
- Linuxインスタンス関連
- Linuxインスタンス登録失敗
- LinuxインスタンスをSSHで登録できない
- Linuxインスタンス:CPUまたはメモリの使用率が高いためログインできない
- Linuxインスタンス:ポートの問題によるログインができない
- Linuxインスタンス:VNCログインエラー Module is unknown
- Linuxインスタンス:VNCログインエラー Account locked due to XXX failed logins
- Linuxインスタンス:VNCへのログインに正しいパスワードを入力しても応答がありません
- Linuxインスタンス:VNCまたはSSHログインエラー Permission denied
- Linuxインスタンス:/etc/fstabの設定エラーによるログイン不能
- Linuxインスタンス:sshd設定ファイル権限に関する問題
- Linuxインスタンス:/etc/profile コールが無限ループする場合
- サーバーが隔離されたためログインできない
- 帯域幅の利用率が高いためログインできない
- セキュリティグループの設定が原因でリモート接続できない
- LinuxインスタンスのVNC使用およびレスキューモードを使用したトラブルシューティング
- CVMの再起動またはシャットダウンは失敗しましたの原因と対処
- Network Namespaceを作成できない
- カーネルおよび IO 関連問題
- システムbinまたはlibソフトリンクの欠如
- CVMにウイルス侵入が疑われる場合
- ファイル作成のエラー no space left on device
- ネットワーク関連の故障
- インスタンス関連障害
- API リファレンス
- History
- Introduction
- API Category
- Region APIs
- Instance APIs
- RunInstances
- DescribeInstances
- DescribeInstanceFamilyConfigs
- DescribeInstancesOperationLimit
- InquiryPriceRunInstances
- InquiryPriceResetInstance
- InquiryPriceResetInstancesType
- StartInstances
- RebootInstances
- StopInstances
- ResizeInstanceDisks
- ResetInstancesPassword
- ModifyInstancesAttribute
- EnterRescueMode
- ExitRescueMode
- InquirePricePurchaseReservedInstancesOffering
- InquiryPriceResizeInstanceDisks
- TerminateInstances
- ModifyInstancesProject
- ResetInstancesType
- DescribeInstancesStatus
- DescribeReservedInstancesConfigInfos
- DescribeZoneInstanceConfigInfos
- PurchaseReservedInstancesOffering
- ResetInstance
- DescribeInstanceTypeConfigs
- DescribeInstanceVncUrl
- Cloud Hosting Cluster APIs
- Image APIs
- Instance Launch Template APIs
- Making API Requests
- Placement Group APIs
- Key APIs
- Security Group APIs
- Network APIs
- Data Types
- Error Codes
- よくある質問
- Related Agreement
- 用語表
操作シナリオ
Tencent Cloudの第6世代S6および第5世代インスタンスS5、M5、C4、IT5、D3は、第2世代インテリジェントIntel®Xeon®スケーラブルプロセッサCascadeLakeを全面的に採用しています。より多くの命令セットや機能を提供して、人工知能のアプリケーションのアクセラレーションに使用するとともに、多数のハードウェア拡張技術を統合することができます。中でも、AVX-512(アドバンスト・ベクトル・エクステンション)は、AI推論プロセスに強力な並列コンピューティング機能を提供し、ユーザーのディープラーニングの効果をより高めることができます。
ここではS5、M5インスタンスを例として、CVMでAVX512を介して人工知能アプリケーションをアクセラレーションする方法を説明します。
モデル選択時の推奨事項
CVMのさまざまなインスタンス仕様は、さまざまなアプリケーション開発に用いることができます。中でも標準型 S6、標準型S5 および メモリ型M5 は、 機械学習やディープラーニングに適しています。これらのインスタンスには、Intel® DL boost学習機能に適応する第2世代Intel®Xeon®プロセッサが搭載されています。推奨される構成は下表のとおりです。
プラットフォームタイプ | インスタンス仕様 |
ディープラーニングトレーニングプラットフォーム | 84vCPUの標準型S5インスタンスまたは48vCPUのメモリ型M5インスタンス。 |
ディープラーニング推論プラットフォーム | 8/16/24/32/48vCPUの標準型S5インスタンスまたはメモリ型M5インスタンス。 |
機械学習トレーニングまたは推論プラットフォーム | 48vCPUの標準型S5インスタンスまたは24vCPUのメモリ型M5インスタンス。 |
有する利点
Intel® Xeon®スケーラブルプロセッサを使用して機械学習またはディープラーニングのワークロードを実行する場合、以下の利点があります。
大容量メモリ型ワークロード、医用画像、GAN、地震解析、遺伝子シーケンシングなどのシナリオで使用される3D-CNNトポロジーの処理に適しています。
シンプルな
numactlコマンドを使用した柔軟なコア制御をサポートしており、小さなバッチのリアルタイム推論にも適しています。強力なエコシステムをサポートしており、大型クラスターで分散型トレーニングを直接実行できるため、大容量ストレージの追加や高価なキャッシュメカニズムを必要とする大規模なアーキテクチャトレーニングを回避することができます。
同じクラスター内で複数のワークロード(HPC、BigData、AIなど)をサポートしており、より優れたTCOを取得できます。
SIMDによってアクセラレーションし、ディープラーニングのアプリケーションプログラムに関する多くの実質的なコンピューティング要件を満たします。
同じインフラストラクチャをトレーニングと推論に直接使用できます。
操作手順
インスタンスを作成
CVMインスタンスを作成します。詳細については、購入画面でインスタンスを作成 をご参照ください。そのうち、インスタンス仕様は、モデル選択時の推奨事項 と実際の業務シナリオに従って選択する必要があります。下図のとおりです。

説明:
インスタンスへのログイン
デプロイ例
実際の業務シナリオに基づき、次の例を参照して人工知能プラットフォームをデプロイし、機械学習またはディープラーニングタスクを実行することができます。
例1: Intel®を使用して、ディープラーニングフレームワークを最適化します TensorFlow*
第2世代Intel®Xeon®スケーラブルプロセッサCascade LakeのPyTorchおよびIPEXでは、演算性能を最大限にアップさせるため、AVX-512命令セットの最適化が自動的に有効になります。
TensorFlow*は、大規模な機械学習とディープラーニングに用いる、人気のフレームワークの1つです。この例を参照して、インスタンスのトレーニングと推論性能を向上させることができます。フレームワークのデプロイに関する情報については、Intel® Optimization for TensorFlow* Installation Guide をご参照ください。操作手順は次のとおりです。
TensorFlow*フレームワークのデプロイ
1. CVMにPythonをインストールします。ここでは、Python3.7を例とします。
2. 以下のコマンドを実行して、Intel®に最適化されたTensorFlow*バージョンのintel-tensorflowをインストールします。
説明:
最新の機能と最適化を利用するため、2.4.0およびそれ以降のバージョンを使用することをお勧めします。
pip install intel-tensorflow
ランタイム最適化パラメータを設定
ランタイムパラメータの最適化方法を選択します。 通常、以下の2つの実行インターフェースを使用して、異なる最適化設定を採用します。実際のニーズに応じて選択できます。パラメータ最適化の設定に関する説明については、General Best Practices for Intel® Optimization for TensorFlow をご参照ください。
Batch inference:BatchSize >1に設定し、1秒あたりに処理できる入力テンソルの総数を測定します。通常の状況では、Batch Inference方式は、同じCPU socketですべての物理コアを使用することによって最高のパフォーマンスを実現できます。
On-line Inference(リアルタイム推論とも呼びます):BS = 1に設定し、単一の入力テンソルの処理(バッチサイズは1)に必要な時間を測定します。リアルタイム推論スキームでは、マルチインスタンスを同時実行して、最高のスループットを得ることができます。
操作手順は次のとおりです。
1. 以下のコマンドを実行して、システム内の物理コアの数を取得します。
lscpu | grep "Core(s) per socket" | cut -d':' -f2 | xargs
2. 最適化パラメータを設定します。以下のいずれかの方法を選択できます。
環境の実行パラメータを設定します。環境変数ファイルに、以下の構成を追加します。
export OMP_NUM_THREADS= # <physicalcores>export KMP_AFFINITY="granularity=fine,verbose,compact,1,0"export KMP_BLOCKTIME=1export KMP_SETTINGS=1export TF_NUM_INTRAOP_THREADS= # <physicalcores>export TF_NUM_INTEROP_THREADS=1export TF_ENABLE_MKL_NATIVE_FORMAT=0
コードに環境変数設定を追加します。実行中のPythonコードに、以下の環境変数設定を追加します:
import osos.environ["KMP_BLOCKTIME"] = "1"os.environ["KMP_SETTINGS"] = "1"os.environ["KMP_AFFINITY"]= "granularity=fine,verbose,compact,1,0"if FLAGS.num_intra_threads > 0:os.environ["OMP_NUM_THREADS"]= # <physical cores>os.environ["TF_ENABLE_MKL_NATIVE_FORMAT"] = "0"config = tf.ConfigProto()config.intra_op_parallelism_threads = # <physical cores>config.inter_op_parallelism_threads = 1tf.Session(config=config)
TensorFlow*ディープラーニングモデルの推論を実行する
Image Recognition with ResNet50, ResNet101 and InceptionV3 を参照して、他の機械学習/ディープラーニングモデルの推論を実行してください。ここでは、benchmarkを例として、ResNet50のinference benchmarkを実行する方法を説明します。詳細については、ResNet50 (v1.5) をご参照ください。
TensorFlow*ディープラーニングモデルのトレーニングを実行する
TensorFlowの性能デモンストレーション
パフォーマンスデータについては、Improving TensorFlow* Inference Performance on Intel® Xeon® Processors をご参照ください。実際のモードと物理構成によって、パフォーマンスデータはある程度異なります。以下のパフォーマンスデータはあくまでも参考です。
レイテンシー性能:
テストを通じて、batch sizeが1の場合に画像分類とターゲット検出に適したモデルをいくつか選択すると、AVX512最適化バージョンでは、最適化されていないバージョンと比べて推論性能が明らかに向上していることがわかります。例えば、レイテンシーに関しては、最適化されたResNet 50のレイテンシーは元の45%まで低減します。
スループット性能:
batch sizeを大きくしてスループット性能をテストし、画像分類やターゲット検出に適したモデルをいくつか選択してテストします。スループット性能データも明らかに向上していることがわかります。最適化後、ResNet 50のパフォーマンスは元の1.98倍までアップします。
例2:ディープラーニングフレームワークをデプロイする PyTorch*
デプロイ手順
1. CVMにPython3.6以降のバージョンをインストールします。ここでは、Python3.7を例とします。
2. Intel® Extension for PyTorc 公式github repo に移動し、インストールガイドに記載されている情報に従って、PyTorchおよびntel® Extension for PyTorch (IPEX)のコンパイルとインストールを行います。
ランタイム最適化パラメータを設定
第2世代Intel®Xeon®スケーラブルプロセッサCascade LakeのPyTorchおよびIPEXでは、演算性能を最大限にアップさせるため、AVX-512命令セットの最適化が自動的に有効になります。
この手順に従って、ランタイムパラメータの最適化方法を設定できます。パラメータ最適化の設定手順の詳細については、Maximize Performance of Intel® Software Optimization for PyTorch* on CPU をご参照ください。
Batch inference:BatchSize >1に設定し、1秒あたりに処理できる入力テンソルの総数を測定します。通常の状況では、Batch Inference方式は、同じCPU socketですべての物理コアを使用することによって最高のパフォーマンスを実現できます。
On-line Inference(リアルタイム推論とも呼びます):BatchSize = 1に設定し、単一の入力テンソルの処理(バッチサイズは1)に必要な時間を測定します。リアルタイム推論スキームでは、マルチインスタンスを同時実行して、最高のスループットを得ることができます。
操作手順は次のとおりです。
1. 以下のコマンドを実行して、システム内の物理コアの数を取得します。
lscpu | grep "Core(s) per socket" | cut -d':' -f2 | xargs
2. 最適化パラメータを設定します。以下のいずれかの方法を選択できます。
環境の実行パラメータを設定し、GNU OpenMP* Librariesを使用します。環境変数ファイルに、以下の構成を追加します。
export OMP_NUM_THREADS=physicalcoresexport GOMP_CPU_AFFINITY="0-<physicalcores-1>"export OMP_SCHEDULE=STATICexport OMP_PROC_BIND=CLOSE
環境の実行パラメータを設定し、Inte OpenMP* Librariesを使用します。環境変数ファイルに、以下の構成を追加します。
export OMP_NUM_THREADS=physicalcoresexport LD_PRELOAD=<path_to_libiomp5.so>export KMP_AFFINITY="granularity=fine,verbose,compact,1,0"export KMP_BLOCKTIME=1export KMP_SETTINGS=1
PyTorch*ディープラーニングモデルの推論の実行とトレーニングの最適化の提案
モデル推論を実行する場合、Intel® Extension for PyTorchを使用してパフォーマンスを向上させることができます。サンプルコードは次のとおりです。
import intel_pytorch_extension...net = net.to('xpu') # Move model to IPEX formatdata = data.to('xpu') # Move data to IPEX format...output = net(data) # Perform inference with IPEXoutput = output.to('cpu') # Move output back to ATen format
推論とトレーニングでは、jemallocを使用してパフォーマンスを最適化できます。jemallocとは、断片化の回避やスケール可能な並行処理に対応していることを強調する、
malloc(3)の汎用実装であり、システムにメモリアロケータを提供することを目的としています。jemallocは、標準のアロケータ機能を超える多くのイントロスペクション、メモリ管理、および変更機能を提供しています。 詳細については、jemalloc および サンプルコード をご参照ください。複数のsocketを使用した分散型トレーニングの詳細については、PSSP-Transformerの分散型CPUトレーニングスクリプト をご参照ください。
パフォーマンス結果
Intelの第2世代Intel®Xeon®スケーラブルプロセッサCascade Lakeをベースとする、2*CPU(28コア/CPU)および384Gメモリシナリオにおける、さまざまなモデルテストのパフォーマンスデータについては、パフォーマンステストデータ をご参照ください。実際のモデルや物理構成が異なるため、パフォーマンスデータにも差異が生じます。ここに記載されているテストデータは、あくまでも参考です。
例3: Intel®AI の低精度最適化ツールを使用してアクセラレーションする
Intel® 低精度最適化ツールは、オープンソースのPythonライブラリです。これは、シンプルで使いやすい、ニューラルネットワークフレームワーク間の低精度定量的推論インターフェースを提供することを目的としています。ユーザーは、インターフェースを呼び出すだけでモデルを定量化し、生産性を向上させることによって、第3世代Intel® Xeon® DL Boostスケーラブルプロセッサプラットフォームでの推論性能をアクセラレーションすることができます。使用法の詳細については、Intel® 低精度定量化ツールコードライブラリをご参照ください。
サポートされているニューラルネットワークフレームワークバージョン
Intel®低精度最適化ツールは以下をサポートしています。
Intel® 最適化したTensorFlow*
v1.15.0、v1.15.0up1、v1.15.0up2、 v2.0.0、v2.1.0、v2.2.0、v2.3.0およびv2.4.0。
Intel® 最適化したPyTorch v1.5.0+cpuおよびv1.6.0+cpu。
Intel® 最適化したMXNet v1.6.0、v1.7.0およびONNX-Runtime v1.6.0。実装フレームワーク
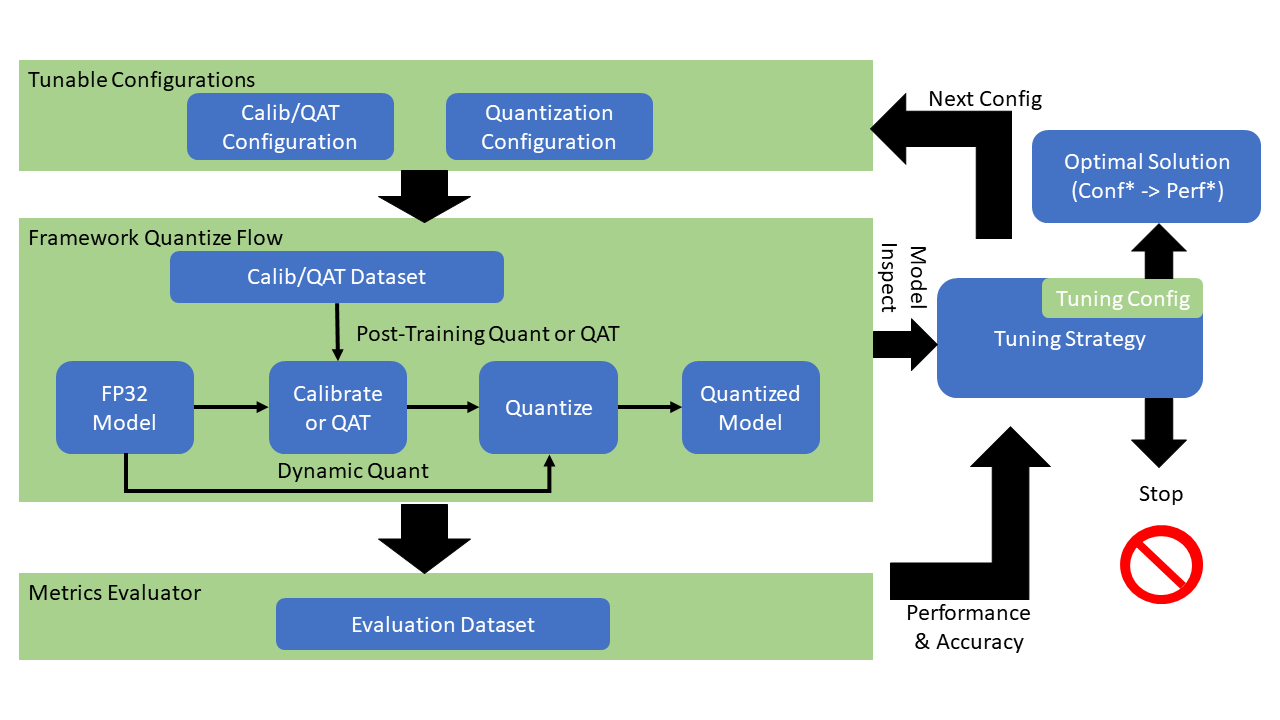
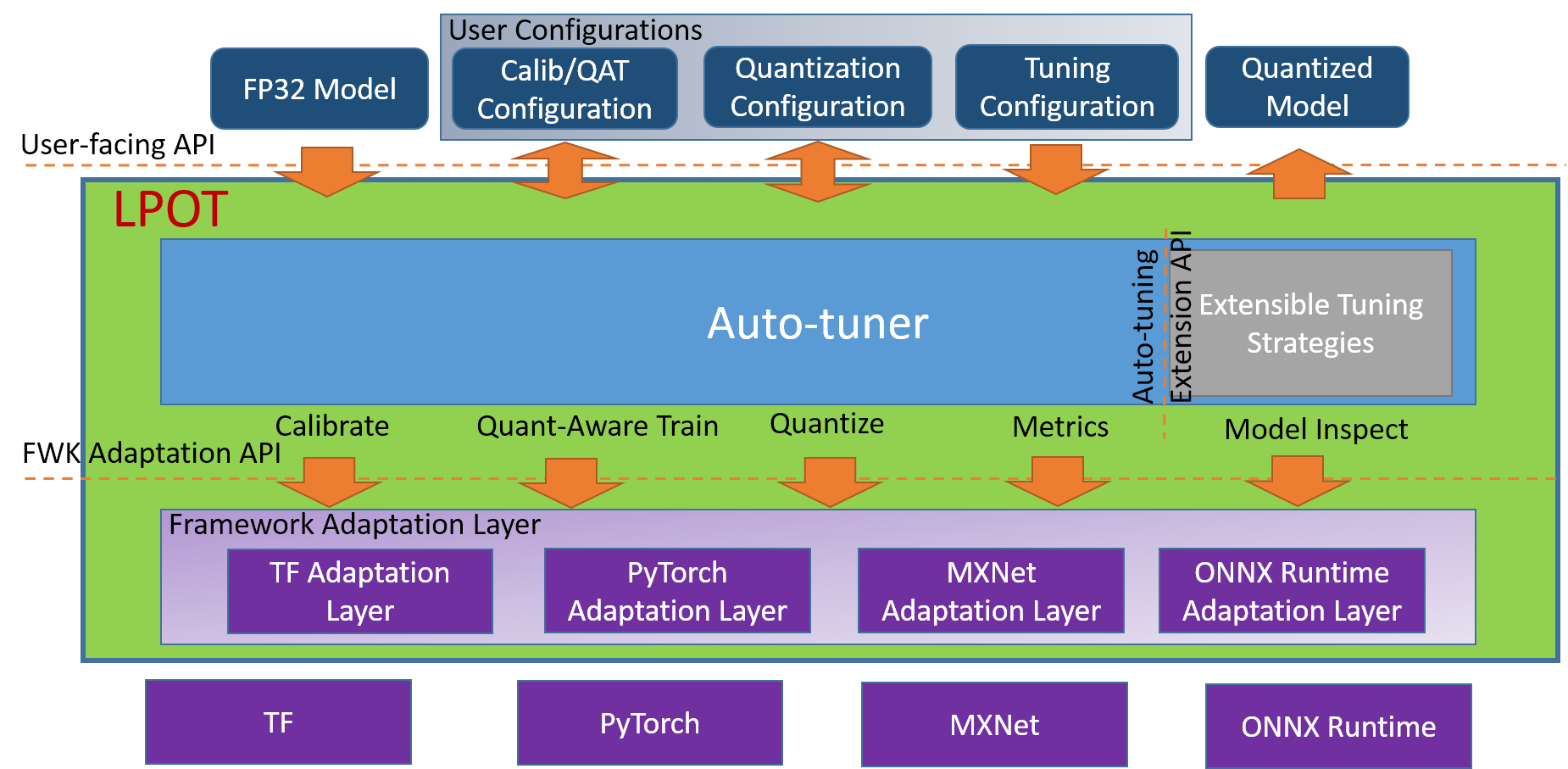
Intel® 低精度最適化ツールの実装フレームワーク略図は次のとおりです。
ワークフロー
Intel® 低精度最適化ツールのワークフローチャートは次のとおりです。
定量的モデルのパフォーマンスと精度の例
Intel® 低精度最適化ツールによって定量化されたモデルの第2世代Intel®Xeon®スケーラブルプロセッサCascade Lakeにおいて得られるパフォーマンスと精度の一部は次のとおりです。
Framework | Version | Model | Accuracy | Performance speed up | ||
| | | INT8 Tuning Accuracy | FP32 Accuracy Baseline | Acc Ratio [(INT8-FP32)/FP32] | Realtime Latency Ratio[FP32/INT8] |
tensorflow | 2.4.0 | resnet50v1.5 | 76.92% | 76.46% | 0.60% | 3.37x |
tensorflow | 2.4.0 | resnet101 | 77.18% | 76.45% | 0.95% | 2.53x |
tensorflow | 2.4.0 | inception_v1 | 70.41% | 69.74% | 0.96% | 1.89x |
tensorflow | 2.4.0 | inception_v2 | 74.36% | 73.97% | 0.53% | 1.95x |
tensorflow | 2.4.0 | inception_v3 | 77.28% | 76.75% | 0.69% | 2.37x |
tensorflow | 2.4.0 | inception_v4 | 80.39% | 80.27% | 0.15% | 2.60x |
tensorflow | 2.4.0 | inception_resnet_v2 | 80.38% | 80.40% | -0.02% | 1.98x |
tensorflow | 2.4.0 | mobilenetv1 | 73.29% | 70.96% | 3.28% | 2.93x |
tensorflow | 2.4.0 | ssd_resnet50_v1 | 37.98% | 38.00% | -0.05% | 2.99x |
tensorflow | 2.4.0 | mask_rcnn_inception_v2 | 28.62% | 28.73% | -0.38% | 2.96x |
tensorflow | 2.4.0 | vgg16 | 72.11% | 70.89% | 1.72% | 3.76x |
tensorflow | 2.4.0 | vgg19 | 72.36% | 71.01% | 1.90% | 3.85x |
Framework | Version | Model | Accuracy | Performance speed up | ||
| | | INT8 Tuning Accuracy | FP32 Accuracy Baseline | Acc Ratio [(INT8-FP32)/FP32] | Realtime Latency Ratio[FP32/INT8] |
pytorch | 1.5.0+cpu | resnet50 | 75.96% | 76.13% | -0.23% | 2.46x |
pytorch | 1.5.0+cpu | resnext101_32x8d | 79.12% | 79.31% | -0.24% | 2.63x |
pytorch | 1.6.0a0+24aac32 | bert_base_mrpc | 88.90% | 88.73% | 0.19% | 2.10x |
pytorch | 1.6.0a0+24aac32 | bert_base_cola | 59.06% | 58.84% | 0.37% | 2.23x |
pytorch | 1.6.0a0+24aac32 | bert_base_sts-b | 88.40% | 89.27% | -0.97% | 2.13x |
pytorch | 1.6.0a0+24aac32 | bert_base_sst-2 | 91.51% | 91.86% | -0.37% | 2.32x |
pytorch | 1.6.0a0+24aac32 | bert_base_rte | 69.31% | 69.68% | -0.52% | 2.03x |
pytorch | 1.6.0a0+24aac32 | bert_large_mrpc | 87.45% | 88.33% | -0.99% | 2.65x |
pytorch | 1.6.0a0+24aac32 | bert_large_squad | 92.85 | 93.05 | -0.21% | 1.92x |
pytorch | 1.6.0a0+24aac32 | bert_large_qnli | 91.20% | 91.82% | -0.68% | 2.59x |
pytorch | 1.6.0a0+24aac32 | bert_large_rte | 71.84% | 72.56% | -0.99% | 1.34x |
pytorch | 1.6.0a0+24aac32 | bert_large_cola | 62.74% | 62.57% | 0.27% | 2.67x |
説明:
表のPyTorchとTensorflowはどちらも、Intelをベースとして最適化されたフレームワークです。完全にサポートされている定量的モデルのリストについては、オンラインドキュメント をご参照ください。
Intel®低精度最適化ツールのインストールと使用例
1. 以下のコマンドを順番に実行し、anacondaを使用してlpotという名前のpython3.x仮想環境を構築します。ここでは、python 3.7を例とします。
conda create -n lpot python=3.7conda activate lpot
2. lpotをインストールするには、以下の2つの方法があります。
以下のコマンドを実行して、バイナリーファイルからインストールします。
pip install lpot
以下のコマンドを実行して、ソースからインストールします。
git clone https://github.com/intel/lpot.gitcd lpotpip install –r requirements.txtpython setup.py install
3. TensorFlow ResNet50 v1.0を定量化します。ここでは、ResNet50 v1.0を例として、このツールを使用して定量化する方法を説明します。
3.1 データセットの準備をします。
以下のコマンドを実行して、ImageNet validationデータセットをダウンロードして解凍します。
mkdir –p img_raw/val && cd img_rawwget http://www.image-net.org/challenges/LSVRC/2012/dd31405981ef5f776aa17412e1f0c112/ILSVRC2012_img_val.tartar –xvf ILSVRC2012_img_val.tar -C val
以下のコマンドを実行して、imageファイルをlabelで分類されたサブディレクトリに移動します。
cd valwget -qO -https://raw.githubusercontent.com/soumith/imagenetloader.torch/master/valprep.sh | bash
以下のコマンドを実行して、スクリプト prepare_dataset.shを使用して、元のデータをTFrecord形式に変換します。
cd examples/tensorflow/image_recognitionbash prepare_dataset.sh --output_dir=./data --raw_dir=/PATH/TO/img_raw/val/--subset=validation
3.2 以下のコマンドを実行して、モデルを準備します。
wget https://storage.googleapis.com/intel-optimized-tensorflow/models/v1_6/resnet50_fp32_pretrained_model.pb
3.3 以下のコマンドを実行して、Tuningを実行します。
ファイル
examples/tensorflow/image_recognition/resnet50_v1.yamlを変更して、quantization\\calibration、evaluation\\accuracy、evaluation\\performance という3つの部分のデータセットパスがユーザーのローカルの実際のパス、つまりデータセットの準備段階で生成されたTFrecordデータが所在する場所を指すようにします。詳細については、ResNet50 V1.0をご参照ください。cd examples/tensorflow/image_recognitionbash run_tuning.sh --config=resnet50_v1.yaml \\--input_model=/PATH/TO/resnet50_fp32_pretrained_model.pb \\--output_model=./lpot_resnet50_v1.pb
3.4 以下のコマンドを実行して、Benchmarkを実行します。
bash run_benchmark.sh --input_model=./lpot_resnet50_v1.pb--config=resnet50_v1.yaml
出力結果は次のとおりです。パフォーマンスデータはあくまでも参考です:
accuracy mode benchmarkresult:Accuracy is 0.739Batch size = 32Latency: 1.341 msThroughput: 745.631 images/secperformance mode benchmark result:Accuracy is 0.000Batch size = 32Latency: 1.300 msThroughput: 769.302 images/sec
例4: Intel® Distribution of OpenVINO™ Toolkit を使用して推論のアクセラレーションを行う
Intel® Distribution of OpenVINO™ Toolkitとは、コンピュータビジョンやその他のディープラーニングアプリケーションのデプロイを高速化できるツールキットであり、Intelプラットフォームのさまざまなアクセラレーター(CPU、GPU、FPGAおよびMovidiusのVPUを含む)をサポートしてディープラーニングを行うとともに、異種ハードウェアを直接サポートすることができます。
Intel® Distribution of OpenVINO™ Toolkitは、TensorFlow*、PyTorch*などを介してトレーニングされたモデルを最適化できます。これには、モデルオプティマイザー、推論エンジン、Open Model Zoo、トレーニング後の最適化ツール(Post-training Optimization Tool)など、一連のデプロイツールが含まれます。
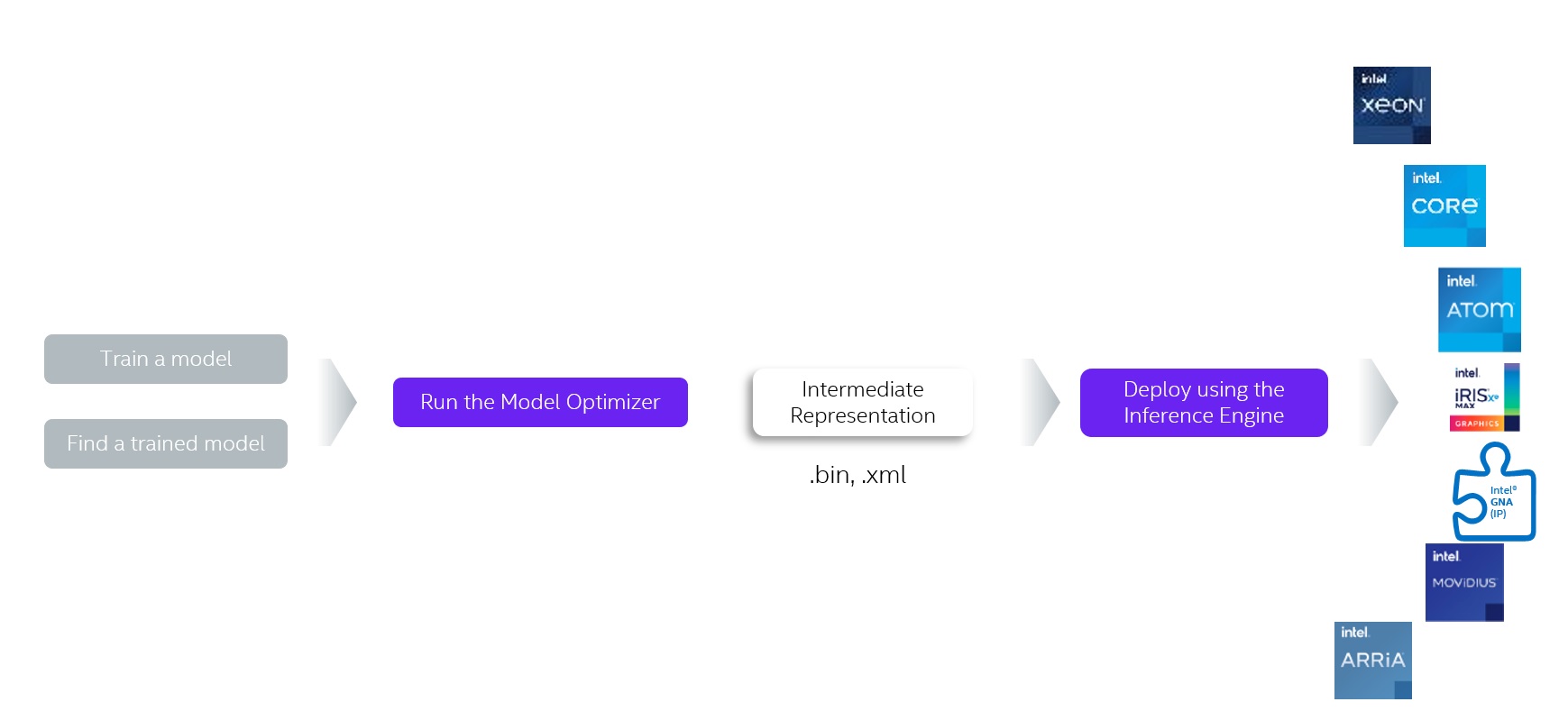
モデルオプティマイザー(Model optimizer):Caffe*、TensorFlow* 、PyTorch*およびMxnet*など、さまざまなフレームワークによってトレーニングされたモデルを中間表現(IR)に変換します。
推論エンジン(Inference Engine):変換されたIRをCPU、GPU、FPGAおよびVPUなどのハードウェアに配置して実行し、ハードウェアアクセラレーションキットを自動的に呼び出して推論性能のアクセラレーションを行います。
ワークフロー
Intel® Distribution of OpenVINO™ Toolkitツールキットのワークフローチャートは次のとおりです。
Intel® Distribution of OpenVINO™ Toolkitの推論性能
The Intel® Distribution of OpenVINO™ツールは、さまざまなIntelプロセッサと高速ハードウェアで最適化を実装します。Intel®Xeon®スケーラブルプロセッサプラットフォームでは、Intel® DLBoostおよびAVX-512命令セットを使用して推論ネットワークをアクセラレーションします。
Intel® Distribution of OpenVINO™ Toolkitディープラーニング開発キット(DLDT)の使用
以下の資料をご参照ください
Intel® Distribution of OpenVINO™ Toolkitのベンチマークテスト

 はい
はい
 いいえ
いいえ
この記事はお役に立ちましたか?